Николай Куликов опубликовал своё руководство по тестированию систем хранения на английском языке, поэтому захотелось получить русский вариант. Данный перевод выполнен ИИ с моими правками (возможны правки формулировок).
Определение критериев успеха для синтетического бенчмаркинга
Исходные данные и вводные
Сбор метрик из существующих систем
Список параметров, которые необходимо определить
- Профиль рабочей нагрузки
- ВМ-испытатели
- Размер виртуального диска и общее использование ёмкости
- Набор активных рабочих нагрузок
- Длительность тестирования и прогрева
- Незавершённые IO или iodepth (OIO)
- Лимиты IOPS
Определение критериев успеха для синтетического бенчмаркинга
Как я уже упоминал в первой части руководства, определение целей и критериев успеха является обязательным шагом для успешного POC. Конечно, критерии успеха могут быть разными, но у них есть нечто общее – они должны следовать правилам S.M.A.R.T:
- Конкретность – цель должна быть конкретной и ясной для всех, кто участвует в тестировании. Не должно быть никаких разночтений, двусмысленных толкований или “само собой разумеется”.
- Измеримость – это означает, что существует метрика или число, которое может однозначно определить прохождение/непрохождение или результат A лучше, чем B.
- Достижимость – требования должны быть реалистичными и достижимыми (хотя бы теоретически) для каждого участника. В противном случае нет смысла тратить на это время.
- Релевантность – здесь это самый важный пункт. Вы должны быть в состоянии прояснить и очень четко показать, почему были выбраны именно такие цели и метрики. Как они связаны с потребностями бизнеса? Почему именно эта метрика или число, а не другая? И будьте осторожны со ссылками на “отраслевые стандарты”, “вот как мы делали это раньше”, “опыт других компаний”. Слишком легко ошибиться и потерять релевантность вашим конкретным бизнес-потребностям.
- Ограниченность во времени – в вашем плане POC должны быть четко и заранее определены временные рамки и сроки.
Цели, а также подробная контрольная программа (описывающая, как именно будут проводиться тесты) должны быть написаны ДО начала POC и одобрены/подтверждены каждым участником.
Я также рекомендую отправить черновик программы участникам, часто они могут дать полезные советы, рекомендации или комментарии, а также для того, чтобы они были готовы. А также быть на связи с производителями/партнерами в процессе бенчмаркинга, особенно, если есть какие-то проблемы или система не смогла достичь поставленных целей. Часто эти проблемы можно легко решить, просто правильно настроив и отрегулировав систему.
Упрощенный пример критерия успеха может выглядеть следующим образом: “Задержка в гостевых ОС, работающих на системе хранения данных в нормальных условиях и полностью рабочем состоянии, должна быть менее 1,5 мс при 95-м процентиле при обеспечении 100 тыс. IOPS с профилем 8K 70/30 Чтение/Запись 90% Случайный доступ”. Рабочая нагрузка генерируется 12 ВМ с 5 виртуальными дисками в каждой, использование хранилища (общий объем данных, хранимых этими ВМ) должно составлять 70% от полезной ёмкости хранилища, размер набора активной рабочей нагрузки составляет 10%, продолжительность теста 2 часа после 1 часа прогрева”.
Исходные данные и вводные
Первой и самой большой проблемой бенчмаркинга, возникающей на этапе подготовки, является сбор данных и метрик для определения целей. В приведенном выше примере было много цифр, таких как профиль рабочей нагрузки, наборы рабочих нагрузок, требуемое время отклика и т.д. Возникает вопрос: “Как, где и от кого я могу получить все эти цифры?”.
В вашей конкретной ситуации вы можете использовать различные способы сбора данных, но наиболее распространенными являются следующие:
- Получить данные непосредственно от владельцев приложений. Теоретически, они лучше всех знают о требованиях своего приложения. Практически, довольно редко команда разработчиков приложений настолько осведомлена и может предоставить метрики, связанные с инфраструктурой. Но в то же время они обладают другой чрезвычайно ценной информацией – пиковые периоды, компоненты и процессы, оказывающие ключевое влияние на бизнес-пользователей, цели по времени отклика, типы сервисов, которые работают внутри приложения, и т.д.
- Профилирование. Мы можем описать необходимые бизнес-сервисы и разложить их на элементы, из которых они состоят. Затем выбираем наиболее критические и/или высоконагруженные компоненты и проводим их глубокий анализ. Для этого мы собираем статистику профиля рабочей нагрузки, связанной с этими компонентами. На этом этапе вы должны получить точный профиль нагрузки приложения, цели по времени отклика и оценку требований к производительности (которые могут быть либо равны текущей нагрузке, либо увеличены). Таким образом, мы сможем воспроизвести рабочую нагрузку на тестируемой системе как можно сходно. Результаты покажут, может ли конкретный сервис работать на тестируемой системе или нет (с точки зрения производительности). Закончив с одним сервисом, мы перейдем к следующему. Помните о возможности взаимного вмешательства в рабочую нагрузку, если ваше хранилище является общим для нескольких сервисов, и заранее изучите возможности нейтрализации или минимизации потенциального влияния.
- Усреднение и обобщение. При таком подходе мы смотрим на проблему с другой стороны – приложения и сервисы являются “черными ящиками”, которые создают нагрузку на вашу инфраструктуру хранения. Они показывают общий профиль нагрузки, поступающей на систему хранения от приложений, а также текущее среднее время отклика и производительность. Мы можем проанализировать профиль нагрузки и паттерны с точки зрения системы хранения и попытаться воспроизвести нагрузку. Только имейте в виду, что заметить более мелкие проблемы производительности, скрытые в этой массе, будет сложнее, в то время как они могут оказать существенное влияние на конкретную службу.
Я рекомендую комбинировать эти подходы для достижения наилучших результатов. Имеет смысл объединить усилия с командами разработчиков приложений, чтобы отдельно проанализировать критически важные для бизнеса приложения и сервисы, потребляющие большую часть инфраструктуры хранения. И дополнить этот анализ более общими тестами инфраструктуры, если есть такая возможность.
Основываясь на своем опыте, я бы рекомендовал вам следующий порядок действий:
- Определите список наиболее важных для бизнеса рабочих нагрузок, сервисов и приложений, которые планируется развернуть на системе хранения данных.
- Обсудите с владельцами приложений их компоненты, специфику, ключевые требования и то, на что следует обратить особое внимание.
- Точно проанализируйте профиль нагрузки этих приложений в деталях низкого уровня.
- Проанализируйте общие показатели инфраструктуры.
- Создайте таблицу, показывающую профиль нагрузки для каждого критически важного приложения и для инфраструктуры в целом.
- Определите критерии успеха для каждого из них (которые обычно содержат приемлемое время отклика и требуемую производительность в IOPS).
- Согласуйте критерии с владельцами приложений и производителями.
После получения профиля рабочей нагрузки существует несколько способов ее воспроизведения. В зависимости от ваших целей и задач, одним из вариантов является создание точно такой же нагрузки (пропускная способность, IOPS с тем же размером блока) и измерение времени отклика для подтверждения того, что оно ниже требуемого уровня. Это эффективный способ для постоянной и стабильной инфраструктуры. В качестве альтернативы можно измерить максимальную нагрузку, которую может выдержать система. Для этого нужно установить время отклика и постепенно увеличивать нагрузку, соответствующую производственной, пока задержка не достигнет порогового значения.
Наконец, важно также проанализировать разумный наихудший сценарий. Наиболее очевидным примером является тестирование хранилища в деградированном состоянии. Мы все знаем, что диски и узлы выходят из строя во время операций, что приводит к снижению производительности и перестройке. Другим примером могут быть массивные запросы на trim/unmap из-за массового удаления данных/ВМ, или пересчета метаданных дедупликации, или низкоуровневого управления блоками и т.д. Идея заключается в том, чтобы гарантировать, что система всегда сможет обеспечить требуемую производительность, даже в частично деградированном или поврежденном состоянии. Но будьте разумны, в большинстве ситуаций нет смысла тестировать абсолютно худший сценарий, где все взорвется и все ужасные вещи произойдут одновременно (если только это не критически важная система безопасности ядерного реактора).
Сбор метрик из существующих систем
Итак, вы выбрали подход к бенчмаркингу и определили, какие системы и компоненты необходимо анализировать. Теперь вам нужно собрать данные и метрики с этих компонентов и инфраструктуры для создания профилей рабочей нагрузки, поэтому давайте обсудим популярные варианты. В моем примере я буду использовать платформу виртуализации VMware, однако большинство инструментов являются кросс-платформенными или имеют эквивалент для других платформ, поэтому подход будет очень похожим. Я начну с высокоуровневых данных, а затем перейду к низкоуровневой статистике.
Прежде всего, исследуйте существующие панели мониторинга. Возможно, там есть некоторое количество нужных и важных данных. Обсудите с владельцами приложений и инфраструктурными командами метрики, на которые они обращают внимание и которые являются для них критическими. Но, скорее всего, вам придется дополнить эти данные с помощью дополнительных источников.
В качестве таких дополнительных источников данных могут выступать различные инструменты оценки инфраструктуры. Одним из самых быстрых и простых инструментов оценки, предоставляющим большинство необходимых метрик, является Live Optics. Я часто использую Live Optics, поскольку это бесплатный и кроссплатформенный инструмент. Он собирает необходимые метрики от 1 до 7 дней с абсолютно минимальными усилиями по настройке. Просто загрузите портативное приложение, запустите его на любой машине, имеющей доступ к инфраструктуре, предоставьте учетные данные только для чтения, выберите сегмент инфраструктуры и продолжительность анализа. Вот и все! По окончании анализа вы загружаете отчет непосредственно с облачного портала. Если ваша среда закрыта от внешнего мира и машина Live Optics не имеет доступа в Интернет, вы можете вручную загрузить исходные данные на портал. Основные преимущества Live Optics – простота использования, достаточно хороший выбор метрик, включая средние и пиковые значения, настраиваемая продолжительность анализа (до одной недели). С другой стороны, он не является настраиваемым, а 7 дней иногда недостаточно, чтобы уловить возможные всплески или пики.
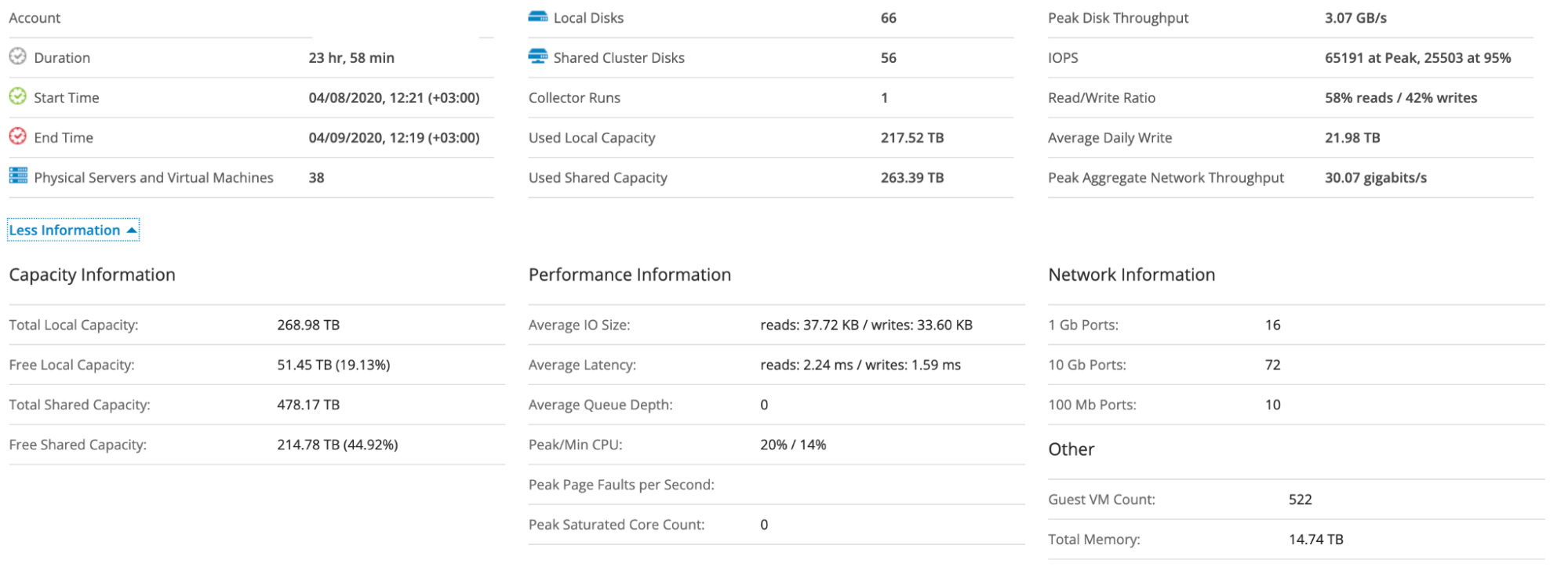
Пример сводного отчета Live Optics.
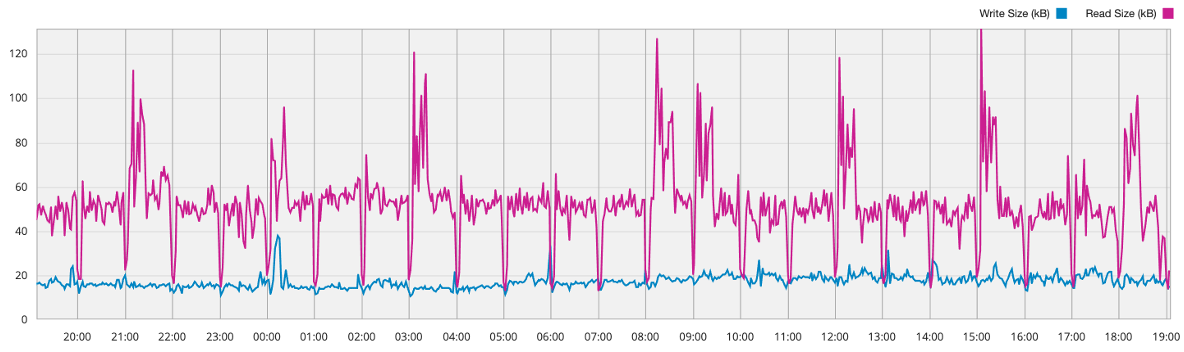
Пример диаграммы размеров блоков Live Optics.
Если вам нужен более гибкий инструмент, вы можете использовать пользовательские приборные панели или отчеты в существующей системе мониторинга. Хорошо, если в вашей системе мониторинга уже есть большинство исторических значений, но если нет – вы можете установить ее заново и начать анализировать данные. Одним из широко используемых решений для мониторинга программно-определяемых ЦОД VMware является vRealize Operations (vRops). Оно по умолчанию хранит большинство необходимых данных в течение длительного времени, но в нем нет готовых панелей и отчетов, которые бы сразу подходили для целей бенчмаркинга хранилищ. Однако создание пользовательских панелей и отчетов с необходимыми метриками в vRops не составляет большого труда. Вы также можете создавать фильтры для конкретной службы или подмножества ВМ. Имейте в виду, что по умолчанию vRops усредняет значения метрик, собранных с интервалом в 20 секунд, в одну пятиминутную точку данных, поэтому иногда трудно обнаружить короткие всплески и пики. Однако это не создает серьезных проблем для долгосрочного анализа.
В идеале вам нужны как метрики высокого разрешения (около 20-60 секунд), по крайней мере, за несколько дней или недель, так и большой объем исторических данных, которые должны учитывать периодические пики (закрытие кварталов, сезонные продажи, регулярные отчеты и т.д.). Если сложно получить и то, и другое одновременно, то можно найти компромисс в виде метрик меньшего разрешения (например, 1-5 минут), но за длительный период, например, за год.
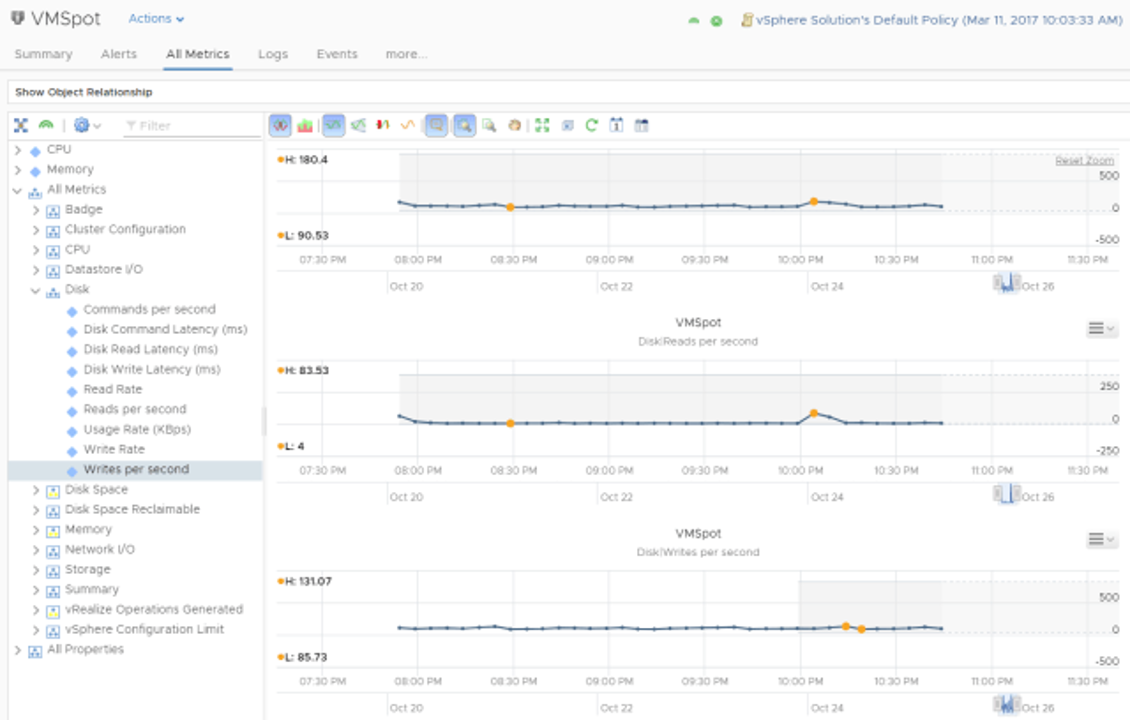
Пример диаграммы пользовательских метрик в vRops.
Наконец, если средние показатели недостаточно хороши для ваших целей, вы можете использовать трассировки. Для платформы VMware существует отличный инструмент под названием vscsiStats. Он собирает данные на уровне устройства vSCSI внутри ядра ESXi и имеет множество данных, необходимых для профилирования хранилища. Например, распределение размеров блоков (не усредненное, а фактическое), расстояние поиска (seek distance), незавершённые операции ввода-вывода, задержки, соотношение операций чтения и записи, и так далее. Более подробную информацию можно найти в статье Using vscsiStats for Storage Performance Analysis – VMware Technology Network VMTN. Для профилирования vscsiStats необходимо выбрать одну или несколько ВМ и начать сбор метрик. По умолчанию, vscsiStats собирает точки данных в течение 30 минут и сохраняет данные в файл для дальнейшего анализа. Однако, имейте в виду, что у этого инструмента есть и недостатки, ограничивающие его использование – он сам может повлиять на производительность, сбор данных происходит на каждом хосте, vMotion виртуальных машин будет препятствовать сбору данных, и это краткосрочный сбор данных.
Если вы используете VMware vSAN, то есть инструмент, который упрощает сбор vscsiStats – vSAN IOInsight. Он собирает те же метрики и показывает результаты в vSphere Client, так что это просто более простой способ сбора трасс. Есть пример метрик из vSAN IOInsight:
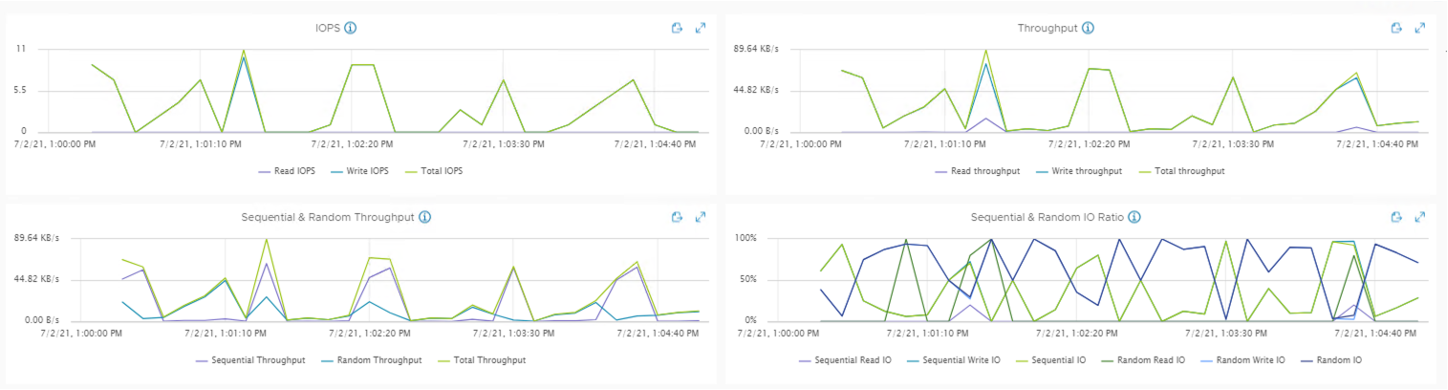
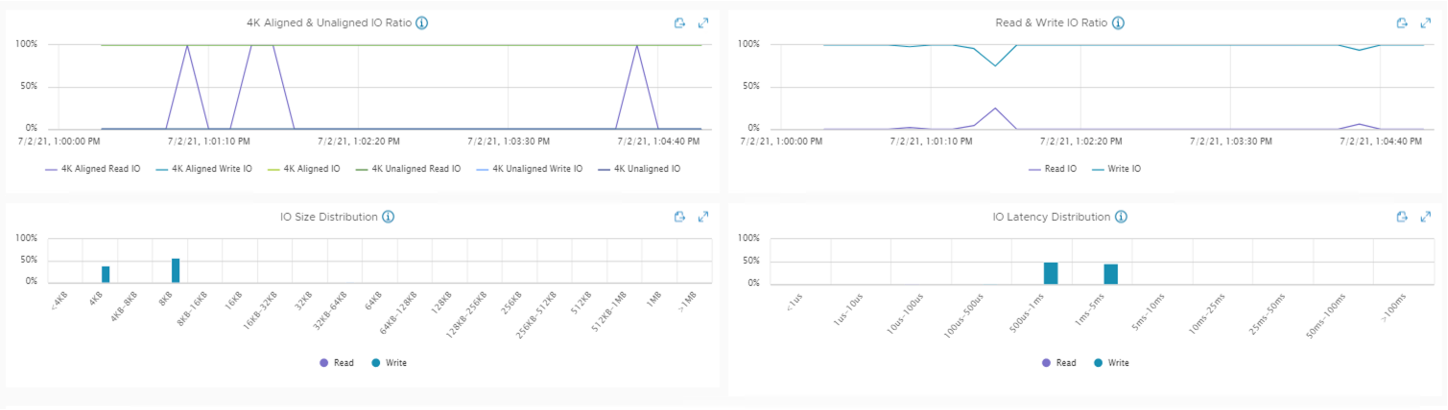 Пример отчета vSAN IOInsight
Пример отчета vSAN IOInsight
В качестве примера аналогичного инструмента для платформ Linux можно привести bpftrace, который может предоставить метрики хранения на уровне гостевой ОС (посмотрите на утилиты bpftrace biolatency, bitesize и другие).
Для наиболее целостной оценки можно комбинировать различные методы и инструменты для достижения комплексной оценки рабочей нагрузки. Используйте инструмент мониторинга для анализа долгосрочных требований к производительности и выявления наиболее нагруженных компонентов. А затем проанализируйте их профили рабочей нагрузки с помощью инструментов трассировки vSCSIstats.
Список параметров, которые необходимо определить
Для запуска тестов необходимо ввести в инструмент бенчмаркинга несколько параметров, каждый из которых может серьезно повлиять на поведение системы хранения данных.
Главный принцип правильного синтетического бенчмаркинга – КАЖДАЯ переменная/параметр/число:
- Должны быть объяснены и понятны, должно быть четкое понимание, почему выбрано именно это число.
- Должны быть записаны и задокументированы.
- Должны быть согласованы с каждым участником POC.
Самый простой способ самопроверки – спросить себя: “Почему я выбрал именно это число, а не другое?”. Если ответ: “Я взял это число из оценки существующей инфраструктуры” или “Это требование бизнеса/владельцев приложений” или “Это рекомендация из лучшей практики, и она подходит для нашего будущего использования”, то все в порядке. Если ответа нет или “какой-то парень в Интернете сказал мне, что это правильно” или “я видел это число в чьем-то бенчмарке”, пожалуйста, сделайте паузу и переосмыслите ситуацию. Подумайте о том, что на самом деле означает этот параметр и как вы можете определить его значение.
Давайте определим список общих переменных, которые вы должны определить на примере HCIBench:
- Профиль рабочей нагрузки:
- Размер блока.
- Соотношение операций чтения и записи.
- Соотношение случайных и последовательных операций.
- Количество виртуальных машин-испытателей и их конфигурация.
- Размер виртуальных дисков.
- Активный рабочий набор.
- Продолжительность теста и время прогрева.
- Количество потоков/выполняемых операций ввода-вывода.
- Лимит IO.
Давайте по порядку объясним, что они означают и как их определить.
Профиль рабочей нагрузки
Профиль рабочей нагрузки определяет конкретный(-ые) паттерн(ы) запросов ввода-вывода, отправляемых в систему хранения. Он имеет следующие размеры:
- Размер блока. Это размер (обычно в КБ или МБ) запроса на чтение и/или запись, отправляемого гостевой ОС/приложением в систему хранения данных.
- Коэффициент чтения/записи. Это отношение операций чтения к операциям записи.
- Соотношение случайных и последовательных операций. Последовательный ввод-вывод – это последовательность запросов на доступ к блокам данных, которые находятся рядом друг с другом. Напротив, случайные IO – это запросы к несвязанным блокам каждый раз (с большим расстоянием между ними). Хорошая иллюстрация здесь.
{kind=link}
Каждый инструмент для сбора метрик, который я описал выше, предоставит вам средний размер блока и соотношение чтения/записи. Таким образом, вам просто нужно исследовать их, и вы получите средние цифры, характеризующие вашу инфраструктуру.
Немного сложнее оценить “случайность” запросов, поскольку для этого необходимо отслеживать LBA-адреса каждого запроса, чтобы определить расстояние поиска. А это возможно только с помощью таких инструментов трассировки, как vSCSIstats или bpftrace. Однако, если вы используете виртуализированную или смешанную среду, то запросы ввода-вывода будут иметь преимущественно случайный характер (исключения из этого правила составляют задания резервного копирования, операции копирования, загрузки и так далее, но они редко напрямую влияют на бизнес-процессы). Следовательно, для таких сред имеет смысл проводить большинство тестов при 90-100% случайных IO.
Чаще всего для описания профиля рабочей нагрузки используются усредненные цифры. Однако, я настоятельно рекомендую проанализировать и воспроизвести точное распределение размеров блоков. Потому что в реальной жизни это всегда неоднородная смесь блоков с разными размерами. Вот пример распределения IO, полученный с помощью vscsiStats для реального приложения:
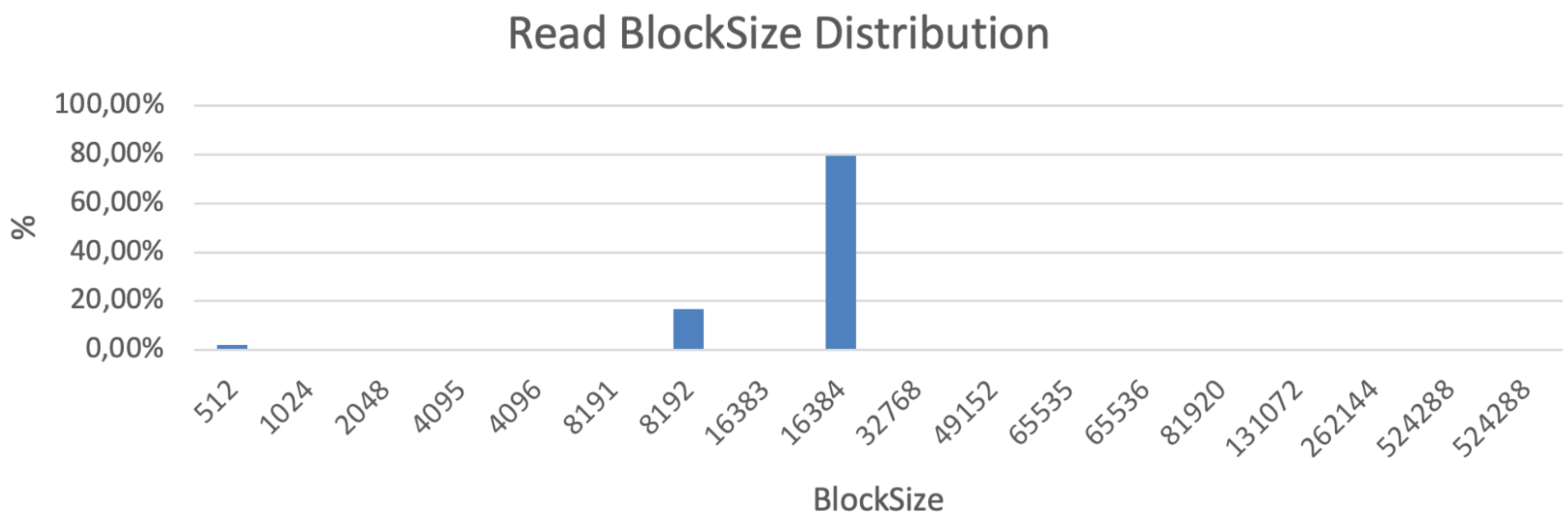
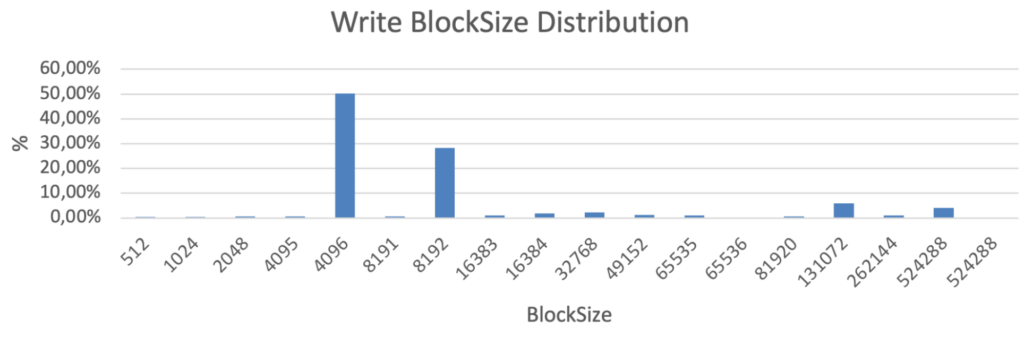
Паттерн распределения размеров блоков ввода-вывода приложения в байтах, полученный с помощью vscsiStats
В этом примере большинство блоков имеют размер 8K и 16K для чтения, а большинство записей – 4K и 8K, но есть также несколько блоков размером ~128K и 512K. И это небольшое количество огромных блоков может иметь существенное значение, поскольку они заполняют буферы записи хранилища и потребляют пропускную способность, препятствуя быстрой обработке небольших блоков. Поэтому, несмотря на то, что наиболее популярный размер блока записи в данном случае составляет 4-8K, а средний ~ 30KB, запускать бенчмарк с 30K блоками, а тем более 4-8K блоками, неправильно.
ВМ-испытатели
Вы также должны определить количество ВМ-испытателей (worker VM) и их конфигурацию, особенно количество виртуальных дисков, количество vCPU (виртуальных ядер ЦПУ) и объем vRAM (виртуальной ОЗУ) на одного испытателя.
Выбор vCPU и vRAM на одного испытателя довольно прост. Идея заключается в том, чтобы избежать узких мест внутри самих ВМ-испытателей и на уровне платформы виртуализации, тем самым обеспечивая, чтобы результаты бенчмарка были изолированы только от системы хранения. Таким образом, вы должны просто убедиться в отсутствии 90-100% загрузки процессора внутри ВМ-испытателей и платформы. В обычных случаях (когда не один испытатель работает со всем хранилищем, а их много), 4 vCPU/8ГБ vRAM или 8vCPU/16ГБ vRAM – это нормально. Наиболее показательным тестом для проверки разумной загрузки процессора является 4K 100% чтение. Сразу после развертывания можно запустить этот тест, чтобы убедиться, что вы не достигли пределов вычислений. Но даже после этого следует периодически проверять загрузку во время тестов.
С количеством виртуальных машин и количеством виртуальных дисков (vmdk) немного сложнее. Вам следует проанализировать примерное соотношение виртуальных дисков на хост в вашей среде и максимально воспроизвести его во время бенчмаркинга. Размещая несколько vmdk, мы избегаем потенциального узкого места с адаптером vSCSI и балансируем нагрузку. В то время, как использование только одного vmdk на ВМ-испытатель может значительно увеличить количество виртуальных машин, что приведет к высоким коэффициентам переподписки vCPU и скроет истинную производительность системы хранения за напряженной платформой. Это может стать проблемой, если ресурсов физических узлов не хватает. Учитывая это, имеет смысл использовать несколько vmdk на одну ВМ-испытатель. Типичное количество ВМ-испытателей – 2-8 ВМ на хост и 2-10 vmdk на ВМ (что в большинстве случаев закрывает диапазон 4-80 vmdk на хост), но всегда лучше проверить количество самостоятельно в своей среде.
Размер виртуального диска и общее использование ёмкости
Размер vmdk определяет, сколько данных вы ХРАНИТЕ. Общая ёмкость определяется как количество ВМ, умноженное на количество vmdk на ВМ, умноженное на размер каждого vmdk. Она не имеет ничего общего с доступом к данным. Например, это может быть холодный архив – запись один раз – чтение почти никогда, но вы все равно храните его. Как определить общую необходимую ёмкость? В случае, если у вас есть уменьшенная система для тестирования, то она должна быть определена как процент от общей ёмкости. Это число должно быть согласовано с вашей будущей средой хранения данных. Например, если вам нужно хранить 100 ТБ полезной емкости, а производитель системы хранения рекомендует не превышать 80% использования из-за влияния на производительность, то вам нужно приобрести 125 ТБ полезной емкости (после raid/spares/system/и т.д.). Таким образом, если производитель предоставляет вам для теста систему ёмкостью 50 ТБ, вы должны заполнить ее на уровне 80%, загрузив 40 ТБ данных.
 Различные уровни использования vSanDatastore
Различные уровни использования vSanDatastore
Кроме того, критически важной частью является возможность ПОДГОТОВКИ этой ёмкости. Это означает, что вам нужно записать весь объем данных перед началом любого теста. Я всегда рекомендую запускать подготовку со случайными данными, а не с нулями, чтобы избежать нежелательного специфического поведения хранилища при обработке большого количества нулей (например, дедупликация, сжатие или обнаружение нулей).
Довольно интересно анализировать влияние использования большой ёмкости, особенно когда вы оцениваете и наихудшие сценарии. В некоторых системах хранения данных использование большой ёмкости может резко повлиять на производительность из-за внутренних процессов. А неожиданный перерасход дискового пространства может произойти из-за ошибки оператора, плохого планирования или других непредвиденных обстоятельств. Таким образом, имеет смысл проводить тестирование не только при запланированном/ожидаемом использовании, но и при более высоких значениях, чтобы понять поведение, риски и потенциальное воздействие.
Набор активных рабочих нагрузок
Набор(совокупность) активных рабочих нагрузок (Active Workload Set или просто Workload Set (WS)) иногда сбивает людей с толку. Чтобы было понятно – это количество данных, к которым вы обращаетесь или, другими словами, активно работаете с ними. Эта тепловая карта является хорошим примером, иллюстрирующим набор активных рабочих нагрузок по сравнению с общей емкостью:
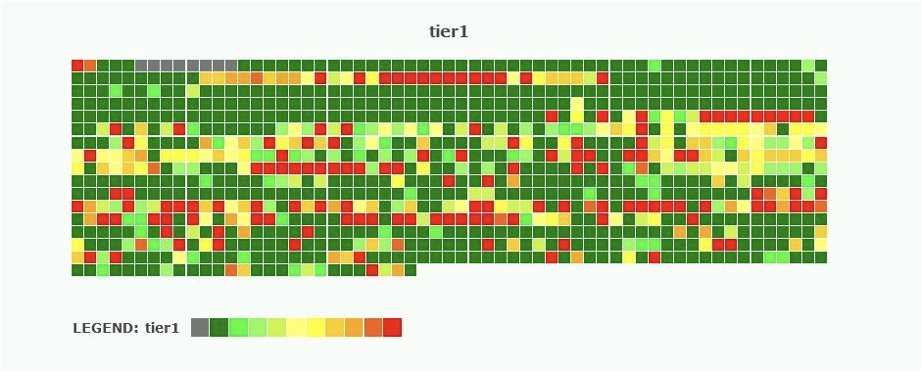 Иллюстрация блоков данных с активным доступом.
Иллюстрация блоков данных с активным доступом.
Здесь общее количество кирпичиков иллюстрирует объем данных, которые вы храните, а их цвет указывает на объем данных, с которыми вы активно работаете. Например, если вы равномерно обрабатываете каждый записанный вами гигабайт, то набор активной рабочей нагрузки будет равен общей емкости, и каждый кирпичик должен быть отмечен красным цветом.
На самом деле, такого почти никогда не происходит. Даже если большая часть данных анализируется, это делается не одновременно – в один день мы работаем с одним блоком данных, а на следующий день – с другим. Кроме того, к большей части данных вообще редко обращаются. Представьте себе системный диск любой ОС – большинство данных, файлов и пакетов используются крайне редко, в то время как другие обрабатываются при каждой перезагрузке.
Проблема заключается в том, как проанализировать объём активной рабочей нагрузки в процентах от полезной ёмкости. И это одна из самых сложных метрик для анализа в существующей инфраструктуре. У нас есть несколько вариантов:
- Ежедневные записи в ТБ. Ее довольно легко получить (производительность записи в МБ/с, умноженная на продолжительность записи, или, говоря более строго, это интеграл пропускной способности записи за время). Проблема здесь в том, что мы не можем разделить “чистые новые записи” и “перезапись существующих записей”. Например, если приложение постоянно перезаписывает 10 ГБ в цикле в течение всего дня, то мы увидим большое количество ежедневных записей, но истинный набор активной рабочей нагрузки составляет всего 10 ГБ. Вторая проблема – он не учитывает чтения, а также объем прочитанных данных. Но, тем не менее, это самый простой способ как-то оценить набор активных рабочих нагрузок.
- Второй вариант – проанализировать размер инкрементной резервной копии. Это также легко сделать (конечно же, вы делаете резервные копии, верно?) и дает реальный объем измененных данных. Но, все равно, никакой ответственности за чтение.
- Третий способ – изучить существующую систему хранения данных. Почти в каждом хранилище есть буфер записи и кэш чтения. Вы знаете размер обоих, и, изучив активность дестейджинга (destaging, перенос данных из буфера записи (уровня кэша) на следующий уровень (уровень ёмкости)), коэффициент промахов кэша чтения, а также степень их заполнения, вы можете более или менее точно оценить объем активной рабочей нагрузки.
Говоря о средних значениях и отраслевых рекомендациях (да, я помню, что просил не полагаться на “средние значения по отрасли”, но иногда этого действительно трудно избежать), вы увидите довольно близкие оценки – набор активных рабочих нагрузок составляет 5-15% от общей емкости. VMware указывает на ~10%. Если вы хотите проверить наихудший сценарий, то 30% – это разумное число, которое хорошо перекрывает обычные ~10%.
Длительность тестирования и прогрева
Во время тестирования происходят процессы, которые приводят к колебаниям производительности. Большинство из них вызвано влиянием различных буферов, кэшей и уровней. Поскольку корпоративные рабочие нагрузки создают непрерывную нагрузку на систему хранения данных, важно измерять не переходные процессы, а стабильную производительность.
Прогрев помогает устранить начальные переходные процессы и перейти в устойчивое состояние. Это период времени, когда испытатели обрабатывают запрошенную рабочую нагрузку, но результаты не фиксируются. Продолжительность прогрева не должна быть меньше, чем требуется для того, чтобы переходные процессы устаканились.
Продолжительность теста должна быть достаточной для анализа поведения системы хранения в долгосрочной перспективе. Важно измерить, насколько последовательны результаты и, в частности, время отклика. Время отклика в стабильном состоянии является критически важной метрикой. Представьте, что ваше приложение получает время отклика 1 мс в течение первых 30 минут, а в течение следующих 5 минут оно увеличивается до 30 мс и возвращается к 1 мс после очистки буферов. Средняя задержка будет в норме, но эти скачки должны быть обнаружены. Таким образом, имеет смысл измерять не только среднюю задержку, но и ее перцентиль (об этом есть замечательная статья в Dynatrace Why averages suck and percentiles are great | Dynatrace news). Вы можете выбрать свой собственный перцентиль для измерения, но наиболее распространенными являются 90-й, 95-й или 98-й. Чем выше перцентиль, тем более стабильную и постоянную задержку вы получите. С другой стороны, при более высоком значении перцентиля вы рискуете пропустить влияние переходов и, возможно, получить более замусоренный результат.
Как же понять, какая продолжительность прогрева и тестирования будет достаточной? Посмотрите на точки данных в отчете FIO/vdbench. Они не только показывают конечные результаты, но и могут фиксировать промежуточные значения во время теста. Посмотрите на них, и если вы заметите значительную разницу за время теста, значит, тесты проводятся не в устойчивом состоянии, и вам следует увеличить продолжительность прогрева. Продолжительность теста можно установить в два раза больше, чем продолжительность прогрева, чтобы быть уверенным, что вы уловите влияние любых дополнительных внутренних операций тестируемой системы хранения данных. Скорее всего, если начальным переходным процессам требуется время X, чтобы устаканиться после начала тестов, то эти дополнительные внутренние процессы должны раньше выявить свое влияние на загруженную систему.
Незавершённые IO или iodepth (OIO)
Незавершённые IO (Outstanding IO, OIO) (примечание переводчика: запросы в очереди, отправленные на исполнение, но СХД ещё не подтвердила их выполнение и они являются не завершёнными, а находятся в “пути следования”, размещаясь в кэшах/буферах/очередях; ещё мне нравится слово “выпущенные”) или iodepth в двух словах указывает на степень параллелизма. Чем больше OIO настроено, тем больше запросов будет отправляться в систему хранения от испытателей параллельно.
Если вы проводите проверочные тесты с количеством IOPS, равным производственной нагрузке, вы можете просто настроить такое же общее количество OIO от испытателей. Но если вы хотите полностью раскрыть потенциал системы хранения, необходимо варьировать OIO, чтобы определить точку наилучшей производительности.
Необходимо понимать, что система хранения данных – это реактивная система. Она ничего не генерирует сама, а только отвечает на запросы своих клиентов. Именно поэтому могут возникать ситуации, когда клиенты создают небольшую нагрузку, с которой система хранения легко справляется. Хранилище используется недостаточно и имеет огромный потенциал, но чтобы продемонстрировать его возможности, нам нужно увеличить нагрузку и количество запросов. Или, наоборот, система хранения может быть полностью использована и не может обеспечить больше IOPS. В этом случае, если вы увеличите количество запросов, вы будете наблюдать более высокие задержки, но не увеличение IOPS. И только где-то посередине существует сбалансированный компромисс между задержками и IOPS в рабочем режиме. Таким образом, зависимость между IOPS и OIO с точки зрения задержек проявляется, как на приведенном ниже графике (примечание переводчика: на графике подписаны размеры пачек операций/команд, которые мы задали и отправили, а задержка по вертикали показывает в какое время они смогли завершиться/исполниться; как видно на уровнях Normal и Overload ждать исполнения команд приходится всё дольше и дольше):
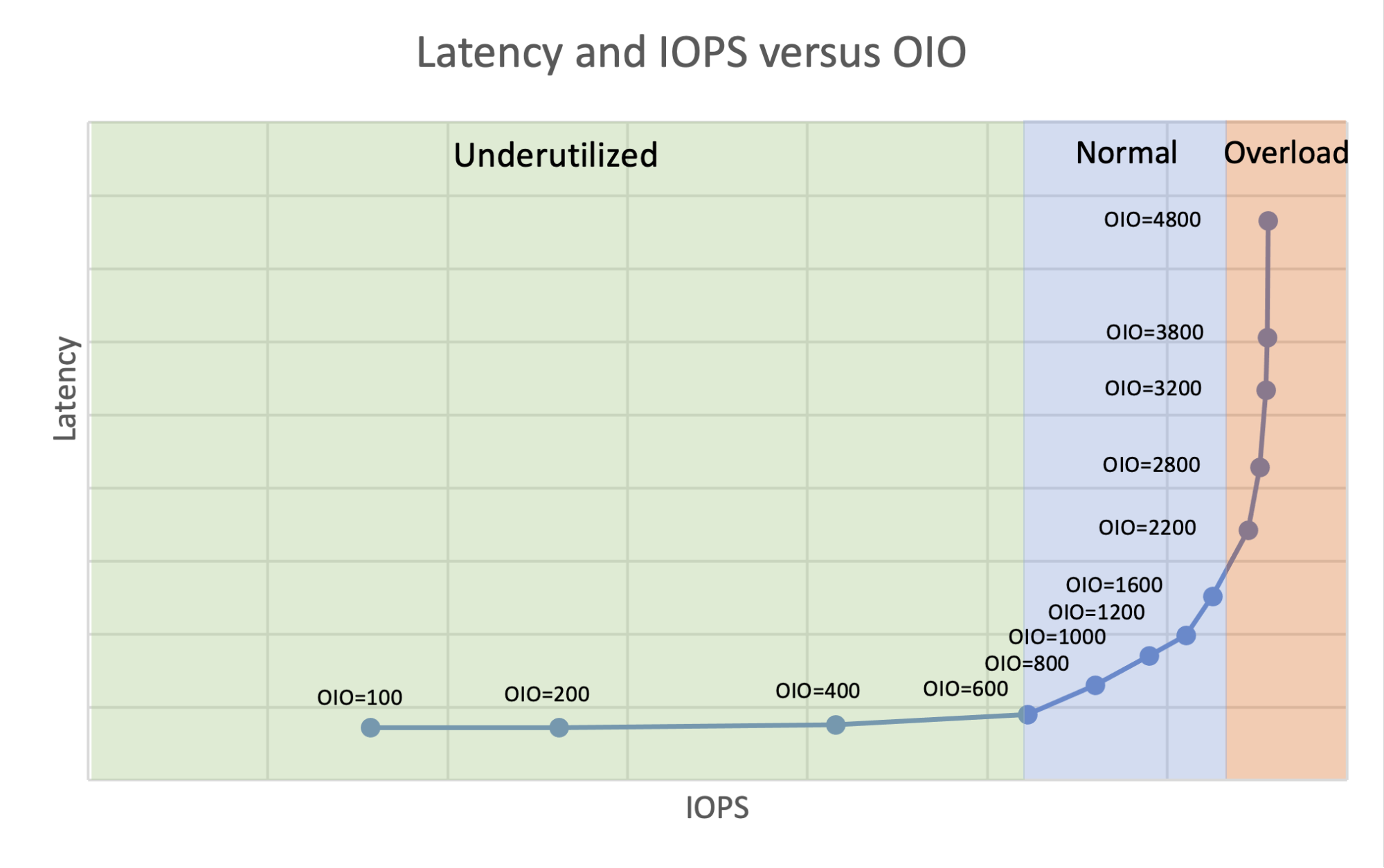 Режимы производительности системы хранения данных.
Режимы производительности системы хранения данных.
Поэтому следует варьировать OIO для получения “оптимального” количества OIO. Что такое “оптимальное”? Это количество OIO, при котором система обеспечивает максимальную производительность (IOPS), а задержка равна или ниже требуемого уровня. Сложность заключается в том, что этот “оптимальный OIO” будет разным для разных профилей рабочей нагрузки, настроек системы и т. д. Это означает, что каждый тест должен проводиться не при одном значении OIO, а при нескольких значениях OIO в окрестностях “оптимальной точки”. Таким образом, вы убедитесь, что нашли правильное значение OIO.
Для этого проведите тесты, начиная с низких значений и постепенно увеличивая их. Анализируя результаты, вы сможете определить, в каком режиме в данный момент находится система хранения данных. Так, если вы видите значительное увеличение производительности при примерно одинаковых задержках, то следует указать еще более высокие значения OIO. И наоборот, если задержки резко возрастают, а производительность практически не меняется, то уменьшите значения OIO. Делайте это до тех пор, пока не получите несколько результатов в нормальном режиме вблизи порога задержек.
В итоге вы получите два графика IOPS/OIO и IOPS/Latency. После этого просто обрежьте верхний из них при требуемом значении латентности, и вы получите “оптимальный OIO”, а также “максимальный IOPS”.
Лимиты IOPS
Кроме того, если вам нужны более точные графики зависимости IOPS/Latency, особенно, в более широком диапазоне значений, вы можете запустить бенчмарк с установленными ограничениями (лимитами, пределами) IOPS. Смысл заключается не в изменении параллелизма, а в изменении частоты запросов при оптимальной выдаваемой OIO.
Для этого после определения оптимального OIO вы запускаете несколько тестов с различными лимитами IOPS от небольшого до неограниченного. Имейте в виду, что начиная с некоторого значения лимитов IOPS, точки (IOPS и latency) начнут сходиться и совпадать. Это нормально, потому что это означает, что вы достигли максимума IOPS, и независимо от того, какой лимит вы установите, вы получите тот же результат.
Заключение
Для того чтобы провести успешный бенчмарк, двигайтесь последовательно и не пропускайте ни одного из этапов – от определения цели к описанию методов и подходов, а затем к конкретным параметрам и условиям проведения тестов.
И помните, что одним из ключевых показателей качественного тестирования является наличие четкого описания ЛЮБОГО параметра, используемого в тесте, а также наличие объяснения, как он связан с задачами и целями.
Если вы будете следовать общим принципам, описанным в этом документе, и адаптировать их к своей ситуации, то можете быть уверены в качестве результатов и выводов.
А теперь перейдем к конкретному примеру в части 3, где большинство моментов, описанных ранее в этом документе, будут рассмотрены на практике.