Николай Куликов опубликовал своё руководство по тестированию систем хранения на английском языке, поэтому захотелось получить русский вариант. Данный перевод выполнен ИИ с моими правками (возможны правки формулировок).
Сценарий и определение целей
ВМ-испытатели
Размер виртуального диска и общее использование ёмкости
Тесты воздействия на производительность набора активных рабочих нагрузок
Анализ влияния продолжительности тестирования и прогрева
Тестирование влияния OIO
Лимиты IOPS
Результаты тестирования
Заключение
Особая благодарность
Приложение A
Что ж, давайте пройдемся по пунктам, изложенным в первой и второй частях, и рассмотрим пример того, как может выглядеть сквозное тестирование.
Как я уже говорил, всегда стоит начинать с определения целей и задач. Истинная цель дальнейших бенчмарков – продемонстрировать на конкретном примере процесс проведения тестирования, а также проиллюстрировать влияние отдельных параметров на результаты теста. Чтобы сделать это ближе к реальности, давайте придумаем некую гипотетическую, но все же реалистичную ситуацию.
Сценарий и определение целей
Для начала представим себе компанию, которая некоторое время назад создала частную облачную инфраструктуру на базе VMware. Но она используется исключительно для задач разработки и тестирования программного обеспечения, и даже в этом случае она обеспечивает лишь частичное покрытие. Остальные сервисы работают на обычной платформе виртуализации VMware vSphere за пределами частного облака. Инфраструктура частного облака, как и продуктивная среда, была построена по традиционной 3-уровневой архитектуре с блейд-серверами, FC-сетью, массивами хранения SAN и внешними аппаратно-определяемыми сетевыми решениями и решениями безопасности.
В таком виде она использовалась довольно долго, но в определенный момент времени заинтересованные стороны бизнеса начали требовать большей скорости и гибкости со стороны ИТ. В ответ на потребности бизнеса было принято несколько стратегических решений:
- Облачный подход. Все и каждый ресурс должен предоставляться из платформы управления облаком.
- Использование гибридного облака. Приложения будут развертываться как в частной облачной инфраструктуре на базе VMware, так и в публичных облаках.
- Самоуправление. Владельцы приложений могут выбирать, где размещать свои рабочие нагрузки, с учетом требований соответствия, безопасности, стоимости, доступности и других требований.
В то же время возникла необходимость обновить инфраструктуру частного облака, поскольку она уже устарела и больше не соответствовала требованиям. При разработке архитектуры новой платформы были определены следующие ключевые требования:
- Гибкое и быстрое масштабирование, которое может осуществляться небольшими шагами. Это важно, поскольку трудно предсказать, где и в каком количестве разработчики будут размещать свои приложения, поэтому инфраструктура должна быть способна быстро адаптироваться.
- Экономическая эффективность. Локальная инфраструктура должна предлагать конкурентоспособную стоимость ресурсов по сравнению с публичными облаками.
- Значительное упрощение эксплуатации инфраструктуры, поскольку многие ИТ-специалисты будут перепрофилированы для создания набора новых высокоценных и простых в потреблении локальных услуг, аналогичных тем, которые доступны в общедоступных облаках.
Для удовлетворения этих требований гиперконвергентная инфраструктура VMware рассматривалась в качестве основного варианта инфраструктуры частного облака нового поколения. Следующей задачей было разработать проект и размеры кластеров, на которых будет работать новое частное облако, включая нижележащее оборудование. Для этого был проведен анализ существующей инфраструктуры с целью получения усредненного соотношения vCPU/vRAM/Диски виртуальных машин. Это позволило произвести грубое определение размеров нового кластера. Однако оценка производительности системы хранения данных требовала подтверждения и уточнения.
Поэтому цели бенчмарка были определены следующим образом:
- Определить, сколько “усредненных” ВМ можно развернуть на кластере с точки зрения производительности хранения, чтобы оценить ТСО усредненных ВМ для нового частного облака и добиться лучшего использования оборудования.
- Понять потенциал производительности кластера.
- Администраторам необходимо изучить особенности гиперконвергентной платформы, ее поведение в различных ситуациях и при различных нагрузках, а также потенциальные узкие места.
Синтетические тесты были выбраны в качестве метода тестирования, поскольку ожидается, что рабочие нагрузки будут очень разнообразными, нет рабочих нагрузок, которые были бы определены как особо важные для индивидуальной оценки, и, кроме того, большинство рабочих нагрузок еще не существует. Вторая причина связана с тем, что использование синтетических бенчмарков позволяет наиболее гибко организовать процесс тестирования и понять поведение системы хранения данных.
Для проведения тестов было решено использовать HCIBench. В первую очередь это было связано с тем, что новая частная облачная платформа будет построена на базе решений VMware. Другой причиной стало то, что программа тестирования включала большое количество более или менее стандартных тестов, с которыми HCIBench очень хорошо справляется.
После того, как мы определились с целями и методами бенчмаркинга, нам необходимо собрать несколько ключевых показателей, позволяющих определить критерии успеха. Во-первых, нам нужно понять, из какого сегмента инфраструктуры мы можем их получить и какие инструменты использовать. Как вы помните, на унаследованной частной облачной платформе компании размещаются в основном малонагруженные тестовые среды. И так будет продолжаться в будущем в связи с ожидаемым ростом объема тестовых сред. Таким образом, мы собираемся использовать существующую систему мониторинга (VMware vRealize Operations Manager) для оценки профиля нагрузки, а также извлечения средних и пиковых значений нагрузки за последний год. После этого мы оценим аналогичные показатели для существующих смешанных продуктивных кластеров, поскольку производственные рабочие нагрузки также предполагается разместить в новом частном облаке.
Допустим, мы получим следующие результаты:
- 8K 70/30 Чтение/Запись 90% Случайный – близко к средним показателям тестовых/разработческих сред.
- 64K 50/50 Чтение/Запись 90% Случайный – что-то вроде наихудшего случая, полученного при анализе продуктивных кластеров.
Таким образом, наши критерии успеха должны быть установлены следующим образом:
- Производительность каждого узла гиперконвергентной платформы должна составлять не менее 25 000 IOPS (наблюдаемый годовой максимум по текущим продуктивным кластерам) при использовании профиля 64K 60/40 90% Случайный с задержкой менее 3 мс.
- Каждый узел гиперконвергентной платформы должен иметь производительность не менее 50 000 IOPS с профилем 8K 70/30 90% Случайный с задержкой менее 3 мс.
- Условия тестирования – ~10-20 vmdk-дисков на узел, нормальное рабочее состояние, загрузка мощностей в соответствии с лучшими практиками производителя, набор активных рабочих нагрузок 10%.
Мы также специально добавим несколько типов синтетических профилей нагрузки, которые и так редко встречаются в инфраструктуре, но которые будут ценны для лучшего анализа поведения системы хранения:
- 4K 100% Чтение 100% Случайный – это синтетическая нагрузка, которая обычно используется для получения максимального IOPS от системы хранения и стрессовой нагрузки контроллеров/процессоров хранения. Паттерн случайного ввода-вывода выбран для придания более “реалистичного” вида.
- 512K 100% Чтение 100% Последовательный – рабочая нагрузка интенсивно использует пропускную способность и выявляет производительность операций пакетного чтения.
- 512K 100% Запись 100% Последовательный – нагрузка, требующая большой нагрузки на запись, вымывает буферы записи контроллеров и показывает производительность операций пакетной загрузки.
Для репликации масштабируемой будущей продуктивной среды тестовая площадка состояла из 6 узлов all-flash vSAN 7.0U2 в конфигурации, практически аналогичной целевой (за исключением вычислительных ресурсов). В то же время у нас есть доказательства того, что масштабирование производительности происходит линейно при условии одновременного увеличения количества узлов и числа виртуальных машин. Для проведения тестов в различных конфигурациях требуется шесть узлов, включая тесты с включенным Erasure Coding FTT=2 (он же RAID 6), для которого требуется минимум 6 узлов. Но для краткости данного руководства все тесты в этом документе будут относиться к политике хранения FTT=1 Mirror (aka RAID1). Подробную конфигурацию тестовой площадки вы можете найти в Приложении A.
ВМ-испытатели
Исходя из оценки существующей инфраструктуры, на каждый узел требуется около 16 vmdk. Поскольку вычислительные ресурсы на каждом узле весьма ограничены, я решил разместить 4 ВМ с 4 vmdk-дисками на каждом узле. Предварительные тесты, а также наблюдения во время основных испытаний показали, что 4vCPU достаточно, чтобы избежать узкого места.
Дальнейшее увеличение количества ВМ или масштабирования ресурсов самих ВМ может только ухудшить результаты из-за высокой переподписки вычислений и конкуренции ресурсов ЦП между ВМ.
Размер виртуального диска и общее использование ёмкости
В условиях тестирования говорится о необходимости заполнения хранилища до рекомендуемых уровней, которые используются при проектировании будущей инфраструктуры.
VMware рекомендует поддерживать свободную ёмкость vSAN на уровне примерно 15-30%, в зависимости от размера кластера и конфигурации. Итак, я рассчитал размер vmdk для достижения общего использования емкости ~75% (~420 ГБ), и это значение было принято за базовое.
Перед этим я провел тест с увеличением использования ёмкости с 17% до 98,7% с каждым профилем рабочей нагрузки, чтобы понять влияние. Самое важное здесь – во время тестов я не менял абсолютный размер активной рабочей нагрузки, заданный в ТБ. Кроме того, тесты выполнялись в устойчивом состоянии (это означает, что данные были записаны и прошло некоторое время, поэтому в кластере не выполнялись активные операции по перебалансировке). На графике производительность при 75% использовании емкости была установлена как 100%.
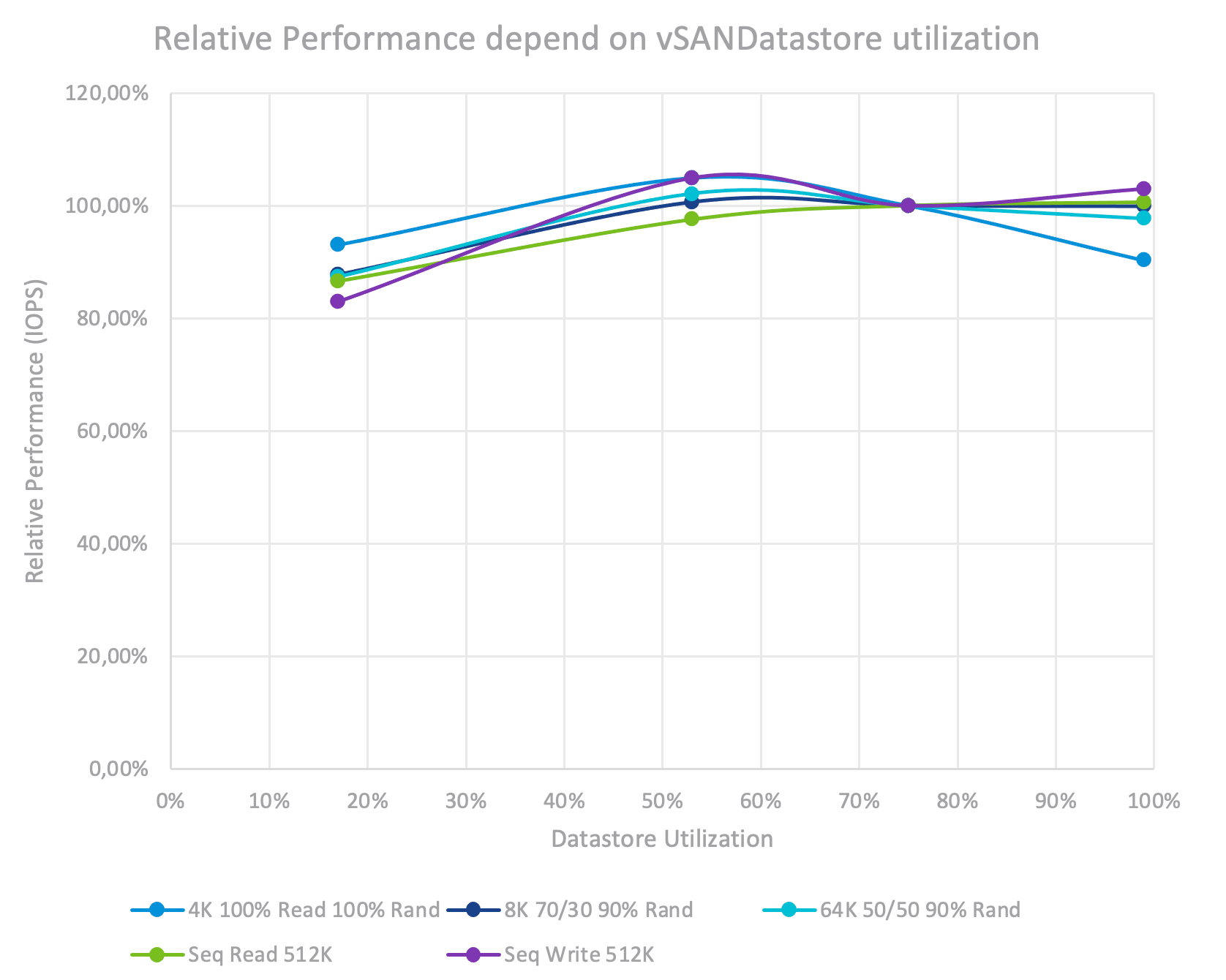 Влияние использования емкости хранилища данных на производительность.
Влияние использования емкости хранилища данных на производительность.
Мы видим, что существенного влияния на производительность более высокой загрузки не наблюдается, независимо от профиля рабочей нагрузки для VMware vSAN. Интересным моментом является снижение производительности на 7-17% при самой низкой загрузке (17%). Это объясняется тем, что на этом уровне большая часть данных находится на SSD с буфером записи без передачи на уровень емкости, что приводит к уменьшению количества SSD, выполняющих запросы ввода-вывода.
Для всех следующих тестов будет использоваться 75%-ная загрузка ёмкости.
Тесты воздействия на производительность набора активных рабочих нагрузок
Теперь давайте исследуем, как размер набора рабочих нагрузок влияет на производительность кластера vSAN. Я изменял размер набора рабочих нагрузок от 1% до 100% и измерял IOPS и задержку для каждого профиля рабочей нагрузки.
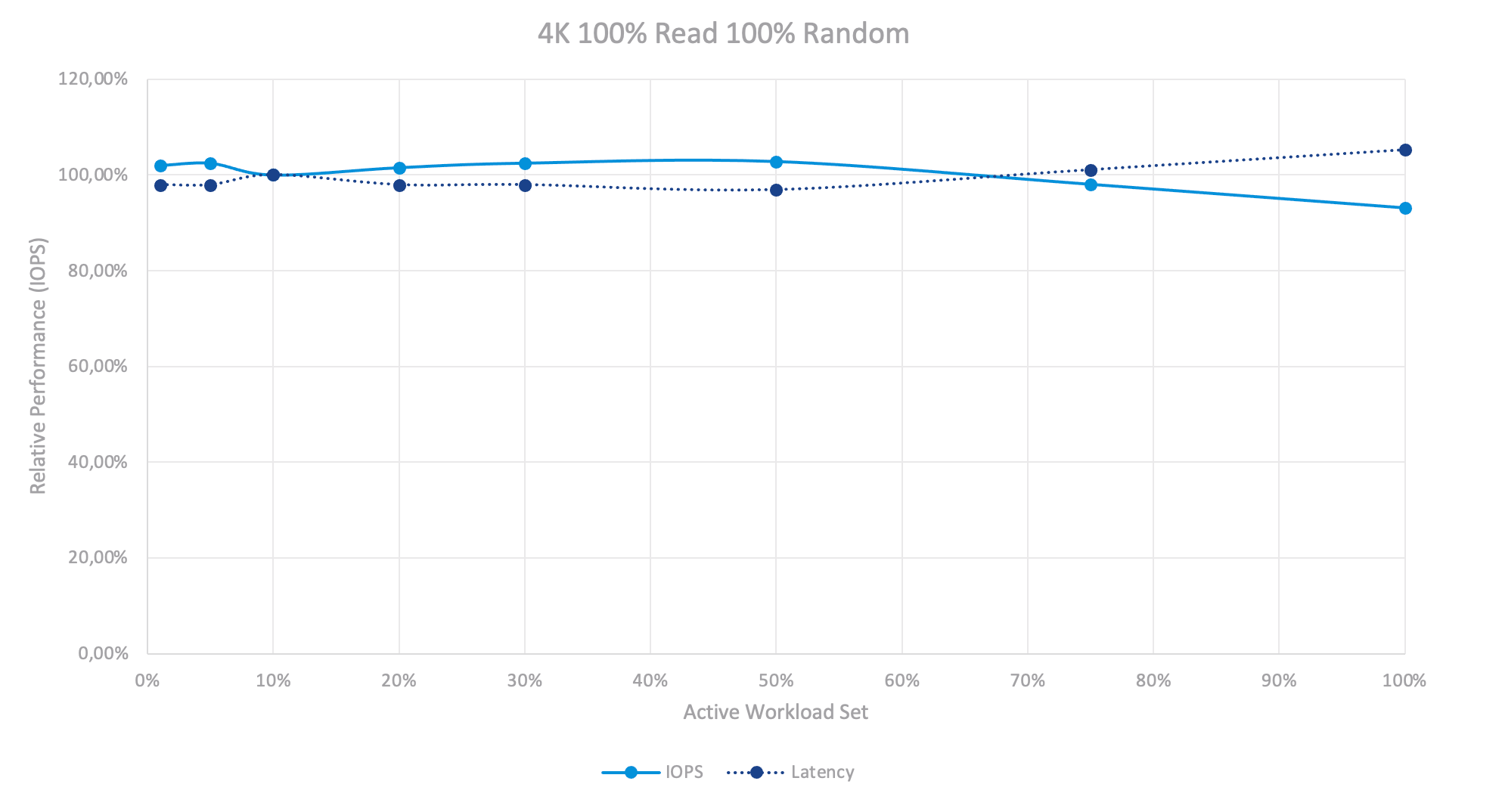 Влияние производительности активного набора рабочих нагрузок во время работы со случайным чтением.
Влияние производительности активного набора рабочих нагрузок во время работы со случайным чтением.
При 4K 100% Чтении мы практически не наблюдаем влияния размера набора активной рабочей нагрузки. Причина в том, что это был All-flash кластер vSAN, и он обслуживает чтения прямо со своего уровня емкости без каких-либо накладных расходов, а SSD на уровне емкости могут обрабатывать их очень быстро. Та же картина наблюдается и в тесте на последовательное чтение.
В то же время совершенно очевидно, что для гибридного кластера будет наблюдаться очень резкое падение производительности после исчерпания кэша SSD.
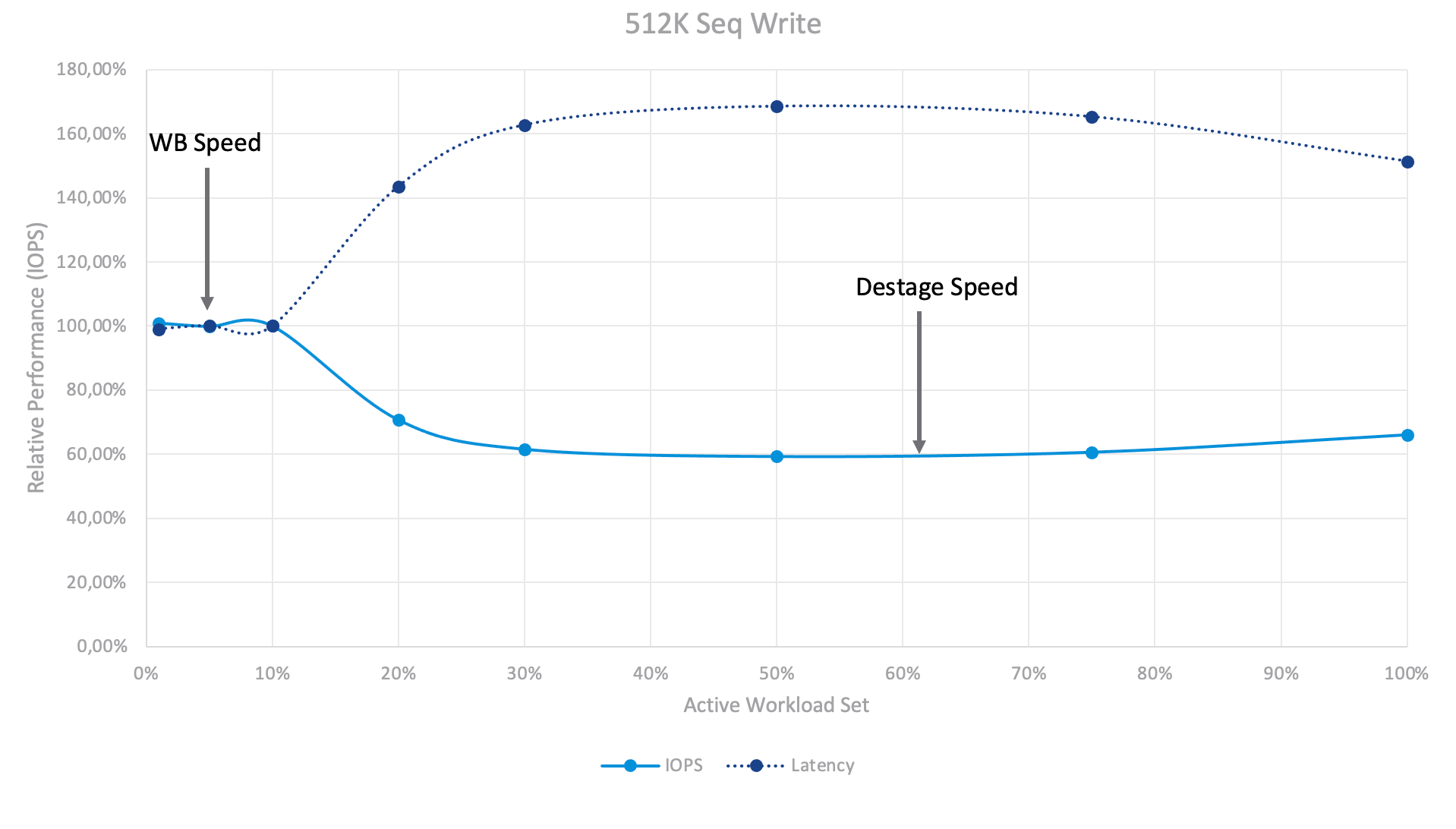 Влияние производительности активного набора рабочих нагрузок при последовательной записи.
Влияние производительности активного набора рабочих нагрузок при последовательной записи.
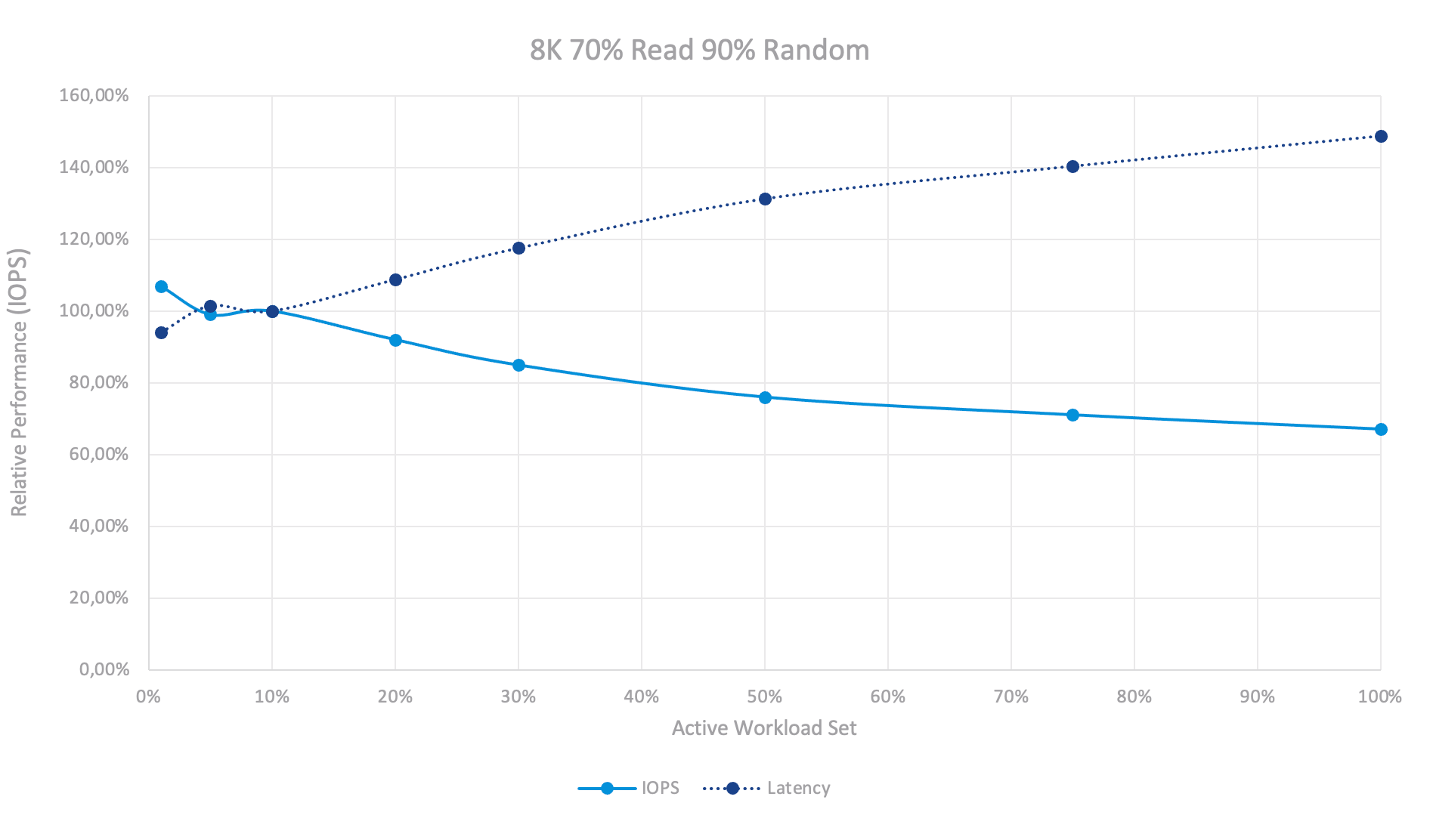
В тесте 512K Последоватальная Запись картина кардинально изменилась. Вы можете видеть два уровня производительности – набор активных рабочих нагрузок 1-10% и 30%+. На уровне 1-10% система реагирует на скорость буфера записи. Мы можем записывать данные в буфер записи очень быстро (с твердотельным накопителем Optane с поддержкой интенсивной записи), но как только наши активные данные больше не помещаются в буфер записи, запускается процесс дестейджинга. Этот процесс влияет на нашу внешнюю производительность – vSAN необходимо освободить некоторое пространство в буфере путем перемещения данных на уровень ёмкости (the capacity tier) для обработки новых данных, поступающих от ВМ-испытателя. При превышении 30%+ дестейджинг становится непрерывным и масштабным, однако система достигает сбалансированного и устойчивого состояния.
 Влияние производительности набора актвиных рабочих нагрузок при смешанной нагрузке.
Влияние производительности набора актвиных рабочих нагрузок при смешанной нагрузке.
Тест смешанной нагрузки, очевидно, представляет собой смесь 100% чтения и 100% записи. Каждое чтение обрабатывается быстро и без каких-либо последствий, записи не такие массивные, поэтому процесс дестейджинга не такой интенсивный. Он влияет на производительность, но не ограничивает ее. Это привело к более плавному графику и меньшему влиянию на производительность в целом.
Выводы о наборе рабочей нагрузки
- Набор активной рабочей нагрузки всегда может повлиять на производительность. Поэтому его следует протестировать.
- Влияние на производительность зависит от различных профилей рабочей нагрузки, а также от различных настроек хранения (дедупликация, сжатие, многоуровневое хранение, кэширование и т.д.).
- Честно говоря, вас не должно сильно заботить точное количество кэша/уровней хранения в системе хранения, если соотношение кэш/ёмкость такое же, как в вашей целевой системе. Думайте об этом как о тестах “черного ящика”.
- Разумно анализировать два случая – нормальный или ожидаемый с активной рабочей нагрузкой ~10% (или любое другое число, которое вы получили, оценив существующую среду) и разумный худший случай ~30%.
- Будьте точны и изменяйте только одну переменную за раз.
- Продолжительность теста должна быть достаточной (я продемонстрирую это позже в документе) для достижения устойчивого состояния системы, когда кэш прогрет, а буферы заполнены.
В следующих тестах я буду использовать 10% WS (“Normal WS”) и 50% WS (“Huge WS”) также для более целостной картины.
Анализ влияния продолжительности тестирования и прогрева
Вот несколько примеров поведения производительности кластера vSAN. Для этого теста я использовал набор рабочих нагрузок “Huge” 50% для лучшей наглядности:
 Производительность во времени во время тестирования случайного чтения.
Производительность во времени во время тестирования случайного чтения.
Для чтения мы видим, что система достигает устойчивого состояния за несколько минут, и разница довольно мала. Это происходит потому, что All-Flash vSAN не имеет большого кэша для чтения (ну, технически, у нее есть небольшой кэш оперативной памяти, но он мизерный по сравнению с набором нагрузки “Huge” в 50%, поэтому коэффициент попадания кэша оперативной памяти близок к нулю, что приводит к отсутствию прогрева кэша).
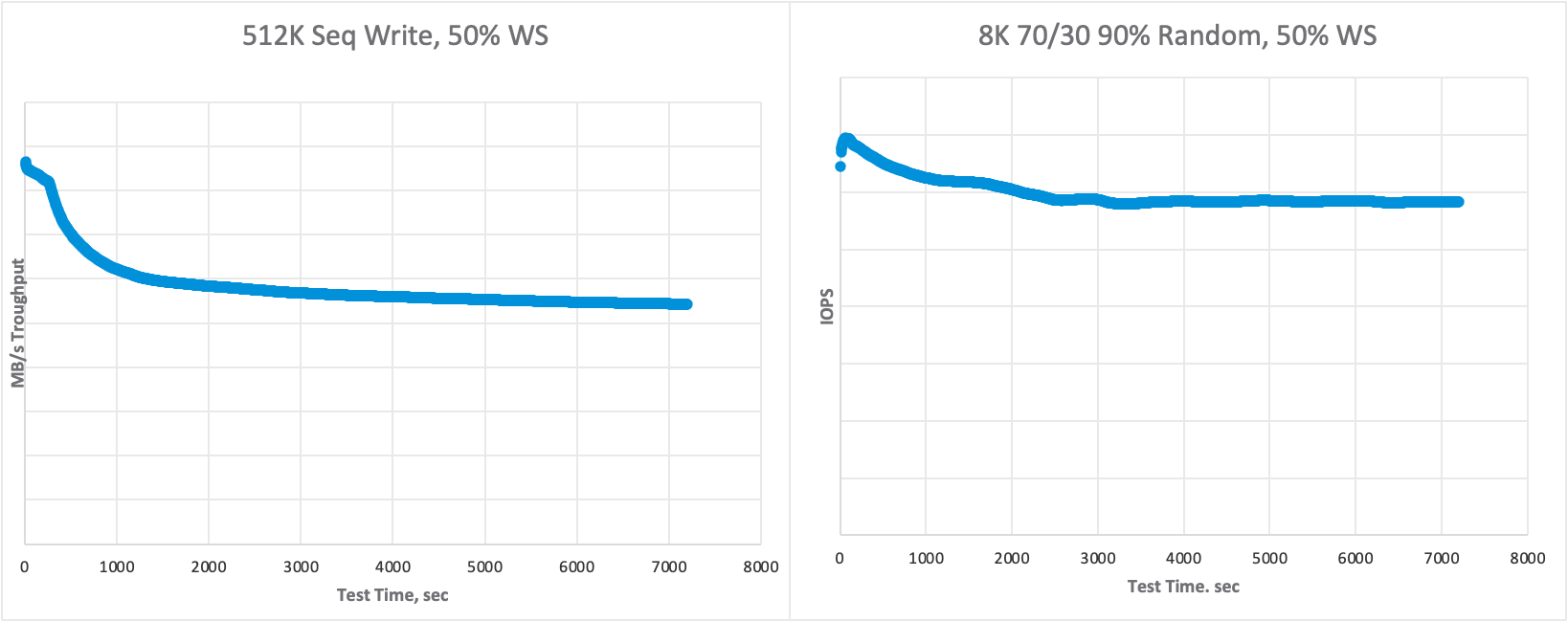 Производительность с течением времени при тестировании последовательной записи и смешанной нагрузки.
Производительность с течением времени при тестировании последовательной записи и смешанной нагрузки.
При записи поведение резко меняется. Из-за буфера записи и процесса дестейджинга, о котором я рассказывал ранее, сначала мы заполняем буфер (и достигаем максимальной производительности), а после заполнения буфера vSAN начинает перенос данных на уровень ёмкости. vSAN управляет интенсивностью переноса данных с течением времени, и его влияние на производительность обычно проявляется в течение 1800-3600 секунд (30-60 минут).
Выводы о продолжительности тестирования и прогрева
С одной стороны, большая продолжительность тестирования и прогрева обеспечивает большую уверенность в качестве результатов:
- Влияние и волатильность значительно варьируются в зависимости от конфигурации теста, системы хранения данных, ее настроек и т.д.
- Разница в производительности между началом теста и его окончанием может быть значительной.
- Чем дольше вы тестируете, тем отчетливее видна волатильность в 95/98 перцентиле.
Но, если мы проводим каждый отдельный тест в течение многих часов или дней, то общее время, которое нам нужно инвестировать, становится огромным. Поэтому нам нужно найти правильный баланс и способы оптимизации:
- Просмотрите точку данных для тестов, чтобы оценить ее стабильность.
- Вы можете значительно сократить продолжительность теста, если выполняете набор связанных между собой тестов. Например, одна и та же рабочая нагрузка, но с разным количеством незавершённых IO. Единственный побочный эффект – открывающие тесты могут оказаться неактуальными из-за малой продолжительности прогрева, поэтому перед записью результатов следует включить несколько “фиктивных тестов”.
- Вы можете использовать более короткие тесты (например, 15-30 минут) в качестве предварительного прогрева, а после того, как вы поймете необходимые параметры, перейти к финальному длительному тесту и записать его результат.
Тесты в этом руководстве проводились с 15-минутным прогревом + 30-минутный тест или с 30-минутным прогревом + 1-часовой тест.
Тестирование влияния OIO
Теперь мы подходим к основным этапам тестирования, а именно к определению производительности системы хранения на необходимых профилях рабочей нагрузки. Для этого мы проводим тесты при различных значениях OIO, фиксируя производительность и задержку. В результате мы получим два графика (на самом деле нам достаточно графика latency vs IOPS, но для наглядности я оставлю оба). Теперь проведем линию, которая обозначит наш порог задержек или адекватный максимум, если он превышает порог, и таким образом, мы сможем понять, сколько IOPS может выдать система в требуемых условиях:
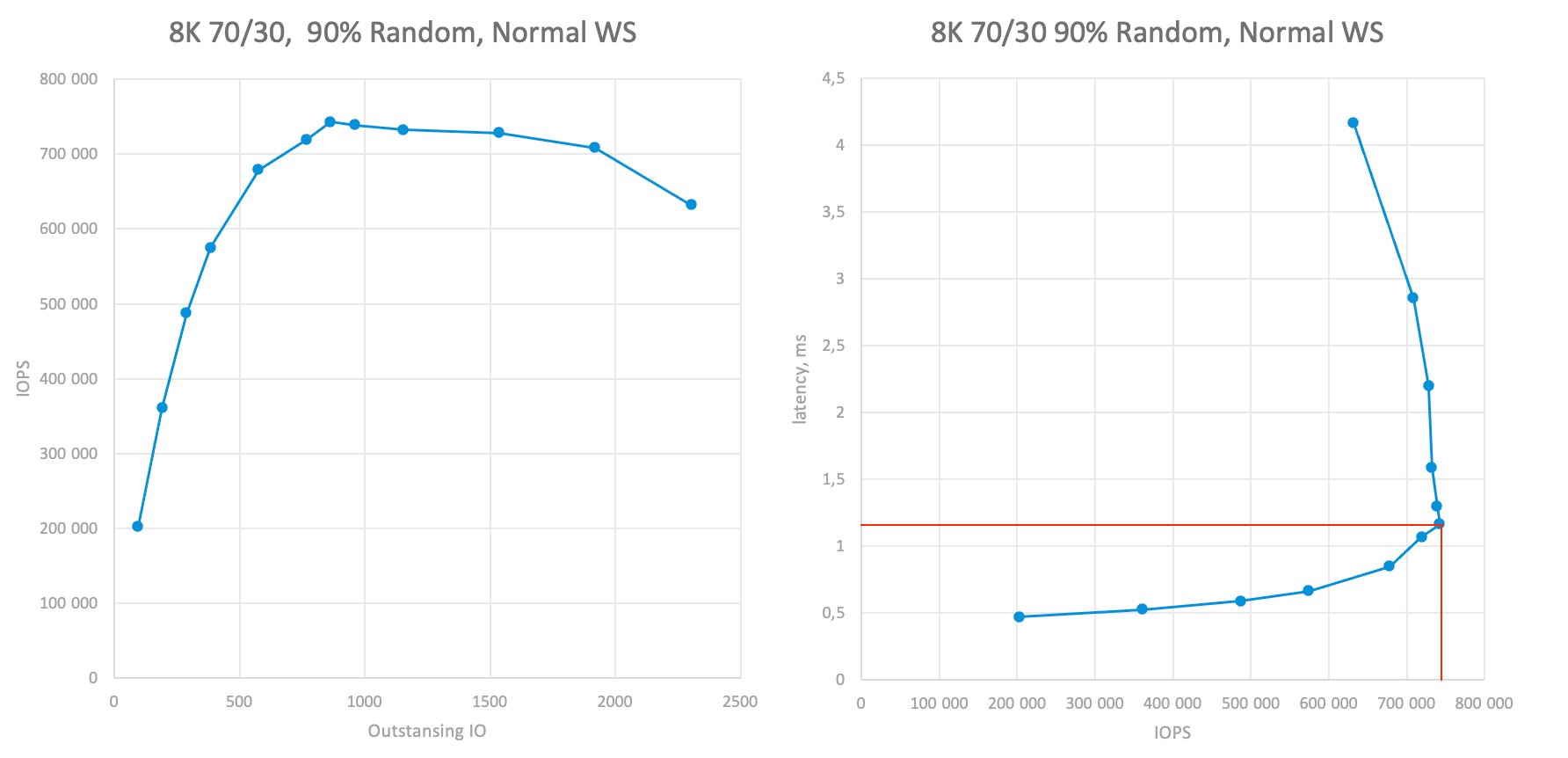 Абсолютные значения производительности кластера vSAN на разных OIO при смешанной нагрузке 8K.
Абсолютные значения производительности кластера vSAN на разных OIO при смешанной нагрузке 8K.
Для профиля рабочей нагрузки 8K 70/30 шестиузловой кластер может достичь ~730K IOPS при ~1,1 мс задержки. Или 115K IOPS на узел, что больше, чем требуется.
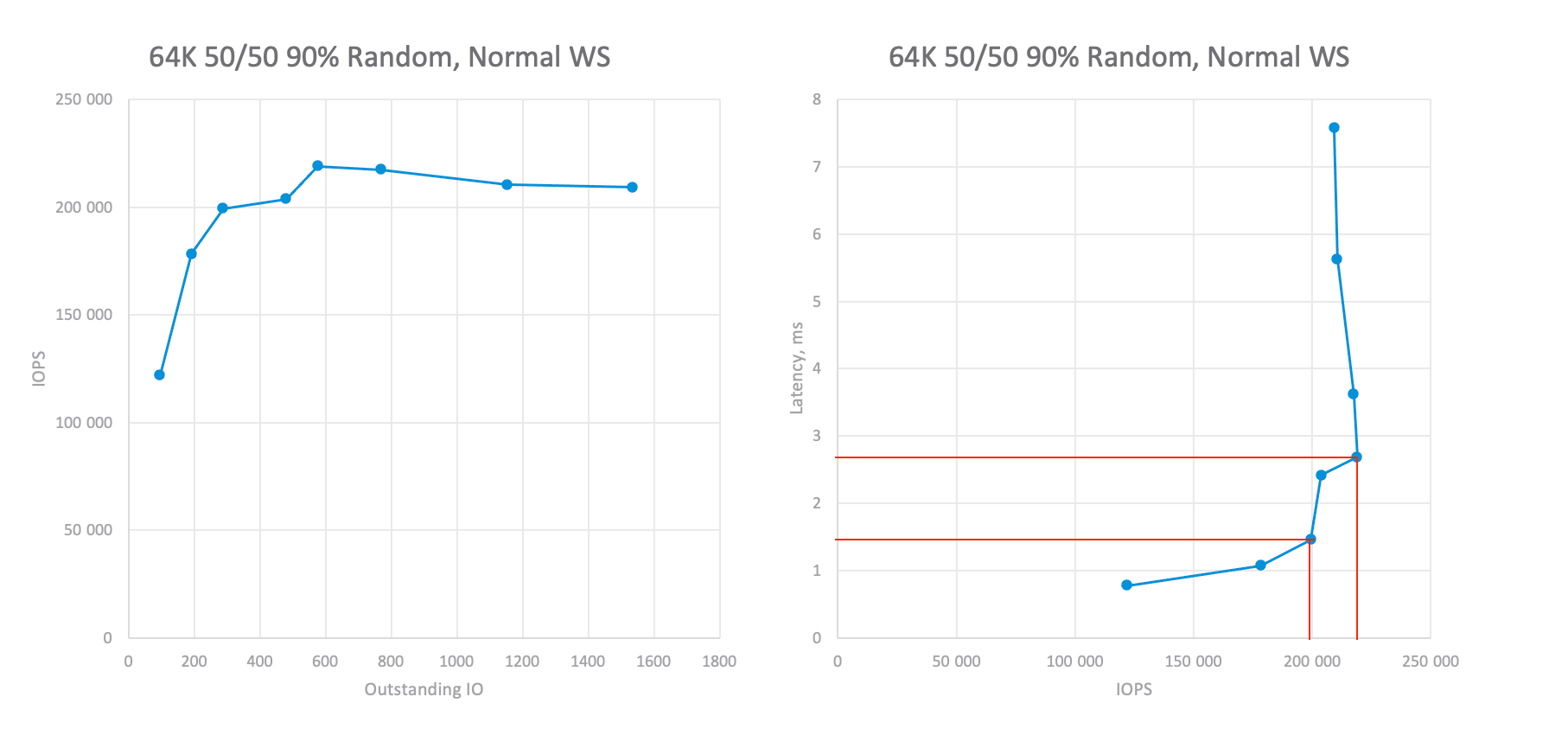 Абсолютные значения производительности кластера vSAN при различных OIO при смешанной рабочей нагрузке 64K.
Абсолютные значения производительности кластера vSAN при различных OIO при смешанной рабочей нагрузке 64K.
Для профиля рабочей нагрузки 64K 70/30 шестиузловой кластер может достичь ~200K IOPS при задержке ~1,5 мс и ~220K при 2,8 мс. Или ~35K IOPS на узел, что также больше, чем требуется.
Кроме того, мы проведем тесты для всех остальных профилей рабочих нагрузок:
 Абсолютные значения производительности кластера vSAN на различных OIO при нагрузке чтения 4K.
Абсолютные значения производительности кластера vSAN на различных OIO при нагрузке чтения 4K.
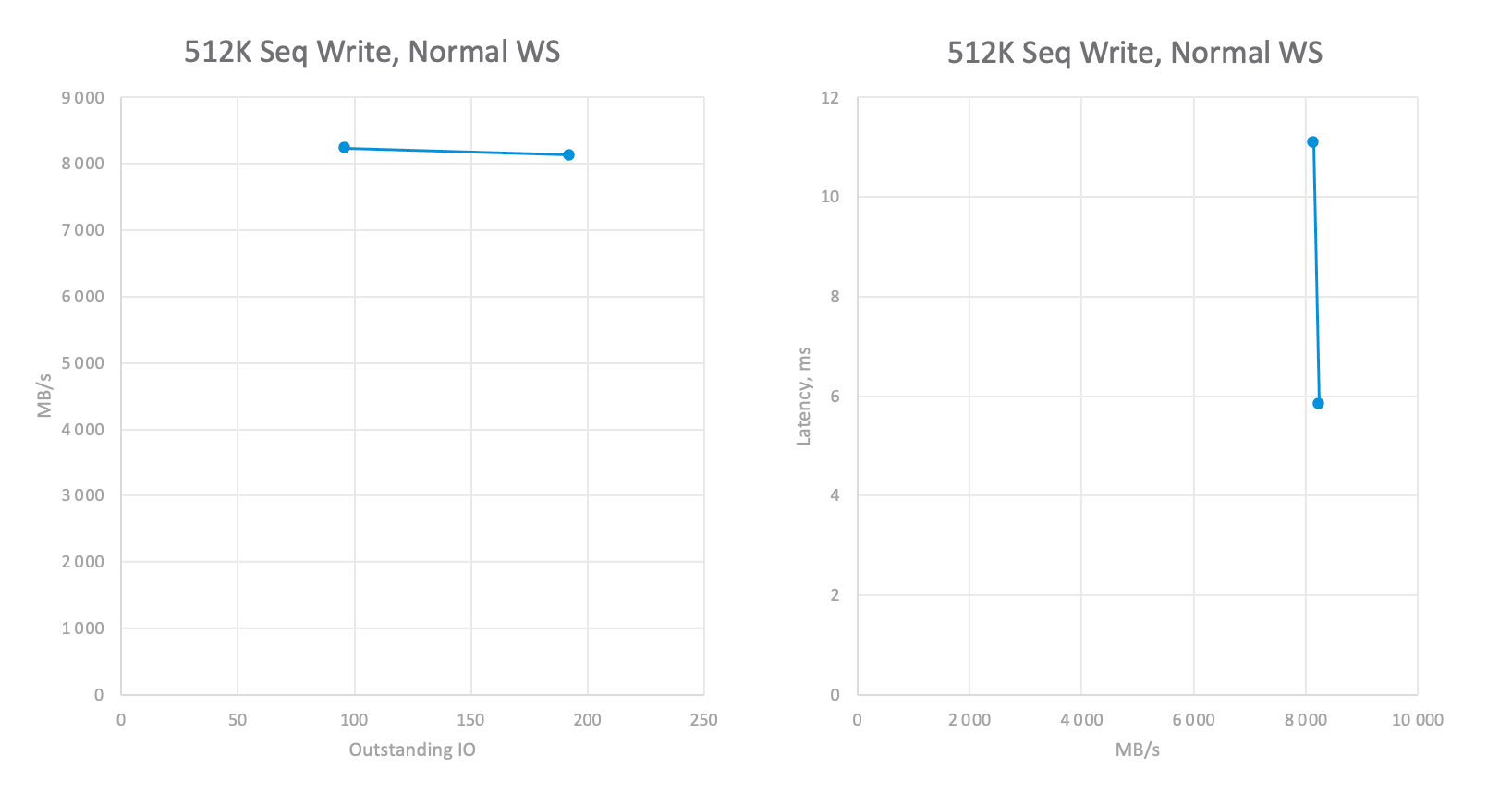 Абсолютные значения производительности кластера vSAN на разных OIO при нагрузке Последовательная Запись.
Абсолютные значения производительности кластера vSAN на разных OIO при нагрузке Последовательная Запись.
 Абсолютные значения производительности кластера vSAN на разных OIO при нагрузке Последовательное Чтение.
Абсолютные значения производительности кластера vSAN на разных OIO при нагрузке Последовательное Чтение.
Выводы об OIO
- Если вы хотите понять потенциал хранилища, запустите бенчмарк с различными значениями для OIO, чтобы получить графики зависимости OIO/IOPS/Latency.
- Из графиков IOPS/Latency получите значение максимального IOPS, достижимого при задержке, равной или ниже ваших требований.
- Это необходимо сделать для каждого профиля рабочей нагрузки или настройки хранилища, поскольку оптимальное значение OIO будет разным.
Лимиты IOPS
В качестве примера я проведу тесты с оптимальным количеством OIO, но разными значениями IOLimit, что позволит мне построить более точную зависимость задержек от IOPS и, в то же время, оценить от почти нулевых значений до максимальных: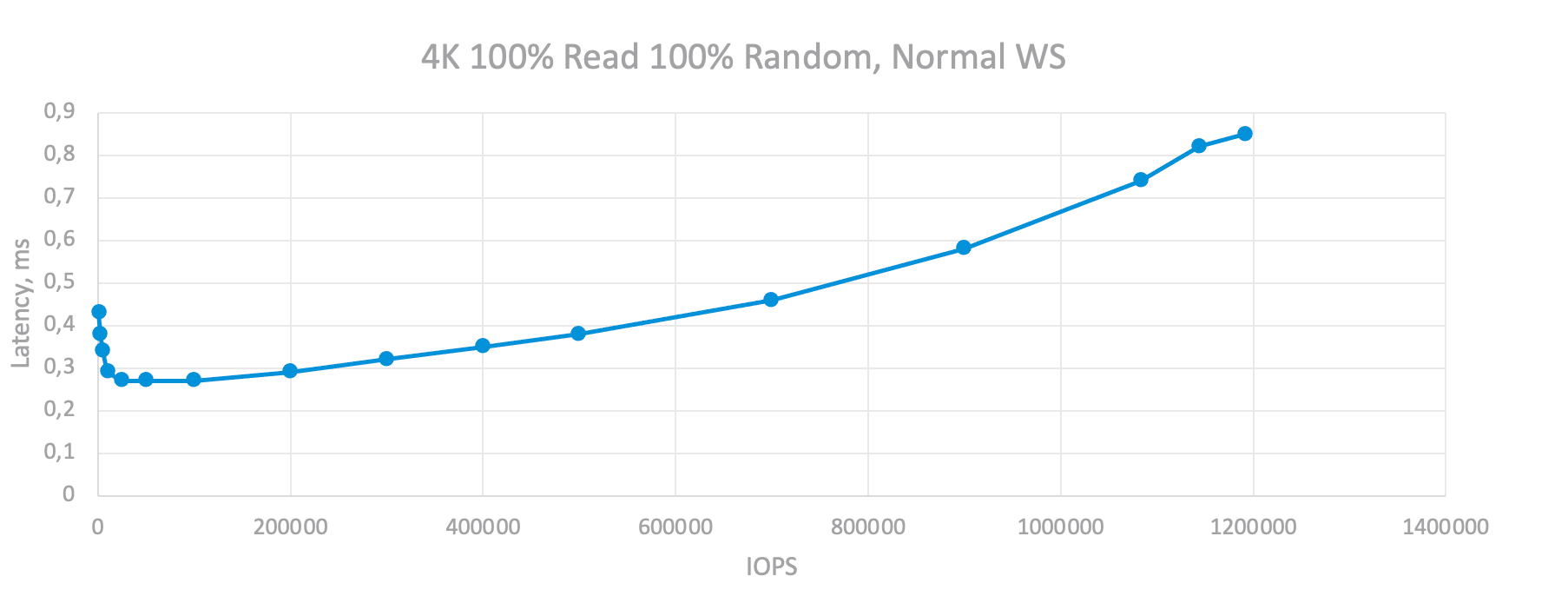
График Latency и IOPS при различных ограничениях IOPS для нагрузки случайного чтения.

График Latency и IOPS при различных лимитах IOPS для смешанных рабочих нагрузок.
Результаты тестирования
Подводя промежуточные итоги тестирования, мы подтвердили жизнеспособность размещения необходимого количества рабочих нагрузок на кластере vSAN в запланированной конфигурации в нормальном рабочем состоянии при использовании политики хранения RAID 1 без Space Efficiency (технологий повышения эффективности хранения).
Мы также узнали и поняли, как каждый из параметров может повлиять на результаты тестирования, а также на что следует обратить внимание и в каких случаях можно ожидать дополнительного падения производительности. Далее нам не обязательно проводить все эти тесты (такие как утилизация, набор рабочих нагрузок и т.д.) нам будет достаточно использовать отдельные выбранные параметры.
Теперь стоит протестировать на соответствие требуемым профилям нагрузки другие политики хранения, чтобы определить, можно ли их использовать для различных рабочих нагрузок. Но для краткости я не буду включать эти тесты в данное руководство, поскольку метод будет точно таким же.
Заключение
Надеюсь, мне удалось показать вам, как общие подходы, изложенные в первой части, могут быть применены на практике. Вы могли убедиться, что, последовательно подходя к задаче, можно относительно легко провести бенчмаркинг и, что самое главное, получить значимый результат.
Также этот материал может быть особенно интересен тем из вас, кто рассматривает и планирует использовать VMware vSAN в своей инфраструктуре. В данном руководстве рассматривается довольно популярная аппаратная конфигурация, которую можно встретить в большом количестве инсталляций vSAN.
Спасибо тем, у кого хватило времени и сил прочитать столь длинные статьи. Я приглашаю всех к обсуждению и прошу поделиться собственным опытом и рекомендациями. Таким образом, мы сможем вместе улучшить эти статьи и принести еще больше пользы сообществу ИТ-специалистов!
Счастливого бенчмаркинга!
Особая благодарность
Я хотел бы выразить особую благодарность Алексею Дарченкову, Михаилу Михееву и Артему Гениеву за огромное количество времени, опыта, компетенций и неоценимую поддержку при создании этого руководства. Без них это было бы невозможно.
Я также выражаю благодарность компании Asbis и особенно Николаю Неучеву за предоставленный демо-стенд vSAN и разрешение провести эти тесты.
Приложение A
Комплектация аппаратного обеспечения:
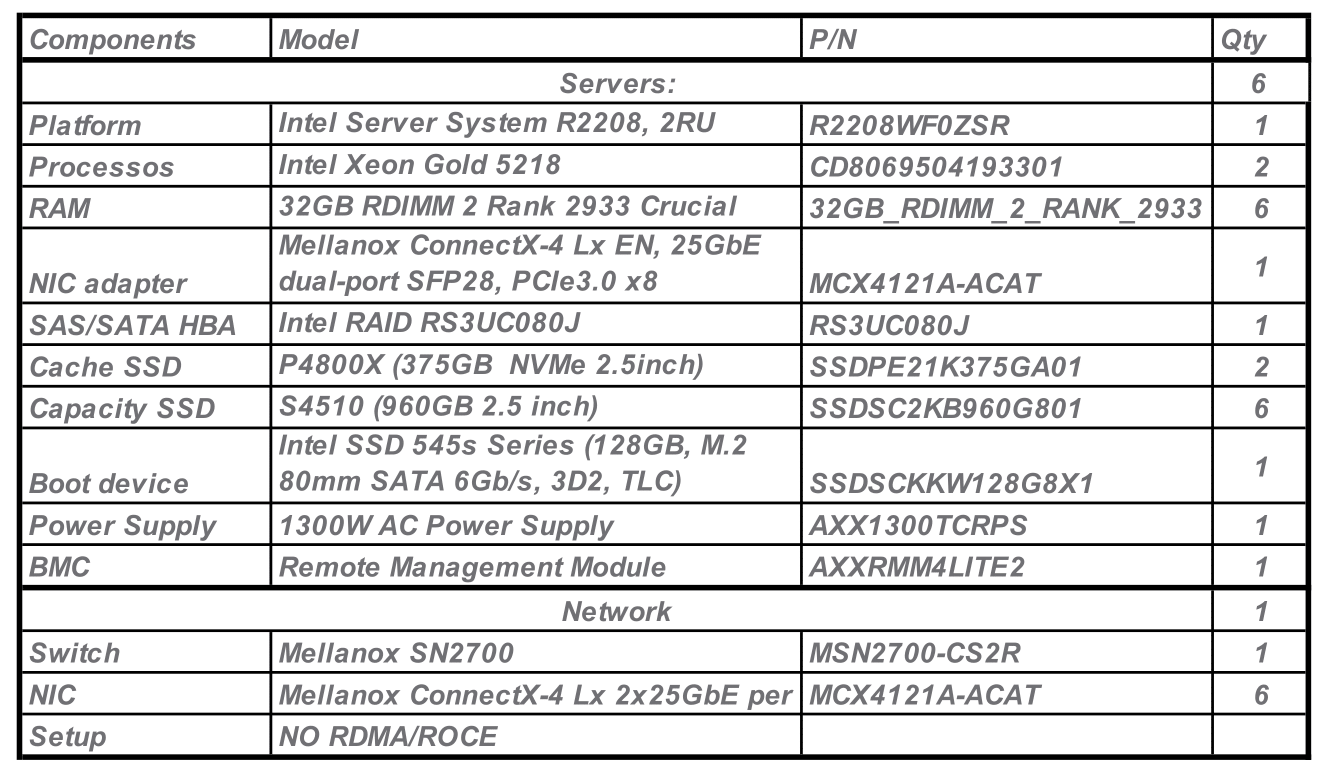
Программное обеспечение:
- ESXi 7.0 Update 2a (сборка 17867351) + vCenter 7.0.2.00100 (сборка 17920168).
- Драйверы и прошивки – последние сертифицированные от VMware HCL в мае 2021 года
- HCIBench 2.5.3 с FIO.
Настройки vSAN:
- Storage Policy – FTT-1 Mirror
- RDMA – Off
- Adaptive Resync – On
- Все остальные настройки установлены по умолчанию.