Как-то Diz задал вопрос: “правда ли, что NFS гораздо лучше, чем SCSI для хранилищ в случае одного большого хранилища? Как ситуация изменилась в 6.x?”
Наше путешествие будет включать в себя следующие пункты:
- SCSI-очереди.
- А что там с NFS?
- Решает ли скорость протокола?
- vSphere 6.x?
- Рекомендации.
SCSI-очереди
Отлично тема очередей раскрыта тут.
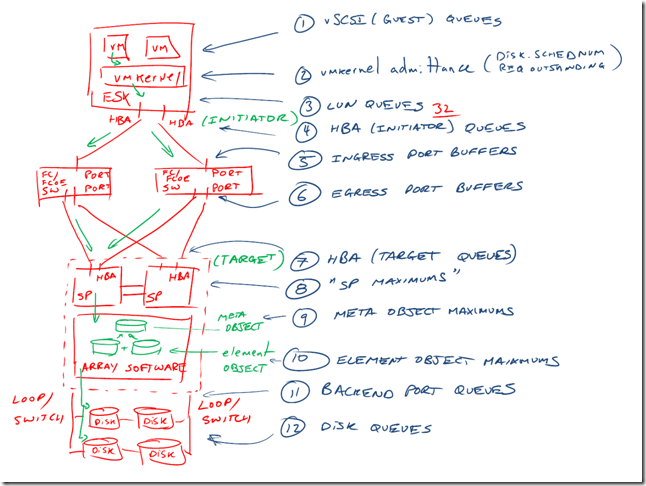 Очередь – это глубина постоянно выполняющихся SCSI-команд.
Очередь – это глубина постоянно выполняющихся SCSI-команд.
Допустим, есть команда “прочитай блок №1”. Пока блок №1 не будет прочитан, а его содержимое возвращено, данная команда занимает “буфер”.
Соответственно, с каждого хоста vSphere до каждого LUN (дискового устройства СХД) есть буфер глубиной 32 команды (может отличаться в разных версиях vSphere у разных HBA).
Поэтому, короткий ответ будет “да” – у одного LUN для виртуализации есть шансы упереться в эту очередь.
Хочу сразу уточнить, что это глубина очереди с одного хоста до одного LUN. Если LUN несколько, и нагрузка на них равномерная, то хост может выполнить большее количество команд без их приостановки.
Типичный вариант “затыкания” в очереди – это очень большой ввод вывод с одного хоста в один LUN (например, несколько тысяч операций ввода-вывода), и не справляющиеся с этим выводом диски.
А что там с NFS
На первый взгляд, NFS-хранилище решает главную проблему SCSI – убирает глубину очереди в 32 на один LUN. Снаружи от хоста до NFS-хранилища подобного “затыка” нет, внутри у сервера глубина очереди сопоставима с SCSI-хранилищами (например, 1024 у HPE’шного рейд-контроллера).
С другой стороны, с балансированием доступа до NFS все несколько неоднозначно. До появления vSphere 6.0 и NFS 4.1 единственным вариантом балансировки нагрузки являлся EtherChannel/LACP, а это, в свою очередь, означало, что от гипервизора до СХД утилизировался один линк.
Также стоит отметить, что NFS-хранилища не предоставляют функционал RDM-дисков.
Если у вас NFS без поддержки функционала VAAI, то вы не сможете создавать толстые VMDK-диски на таком хранилище.
Решает ли скорость протокола?
И да, и нет. Разумеется, обогнать NFS поверх 1Гбит/с сможет даже “черепаший” FC4Gb, который уже давно устарел.
Текущие “топовые” коммутаторы FC поддерживают до 128Гбит/с, Ethernet – до 100Гбит/с. 10Гб/с Ethernet и 8Гб/с FC уже давно стали легкодоступной попсой.
Учтите, что полоса утилизируется только в случае последовательных операций (а это как правило бэкап или восстановление).
Возьмем данные из технической спецификации на массив начального уровня HPE MSA 2050:
- 72 SAS15k, организованные в кучу Raid5, дают в сумме 5,29ГБ/c на последовательное чтение;
- 8 SSD, объединенные в кучу Raid1, выдают на чтение 220,8 тысяч IOPS по 8КБ или 1,68ГБ/c на случайное чтение.
Естественно, это цифры, полученные из максимально допустимого распараллеливания ввода вывода. В реальной жизни на аналогичном железе результаты будут скромнее .
Если подытожить, то скорости близкие или превышающие 10Гбит/с вы можете получить либо с SSD, либо с огромной кучи HDD с последовательными операциями ввода-вывода.
С другой стороны, есть ряд исследований, показывающих, что Fiber Channel лучше чем Ethernet (раз, два), если речь идет о достаточно высокой утилизации канала.
vSphere 6.x
В vSphere при использовании одного хранилища VMFS каждый хост будет иметь пресловутую глубину очереди и сможет в нее упереться. Это SCSI и ничего тут не поделаешь.
Так как VMFS кластерная система, она добавляет свои накладные расходы для того, чтобы ее нельзя было повредить одновременной записью.
Соответственно, VMware направляло свои силы в двух направлениях:
- Оптимизация VMFS. Это VMFS5&VAAI ATS Locking (желательно иметь поддержку этого функционала со стороны СХД). А также дальнейшее улучшение VAAI ATS в VMFS6 (поддерживается в vSphere 6.5). Кроме того, VMFS6 позволяет выполнять несколько операций с тонкими VMDK-дисками с одного хоста. В предыдущих версиях VMFS хост был обязан выполнять операции с тонкими дисками последовательно по одной.
- Появление функционала VVoL, который позволяет фактически “эмулировать” создание дискового устройства (LUN) для каждого VMDK-диска виртуальной машины.
Файловая система VMFS поддерживает ее “растягивание” на 32 дисковых устройства (так называемые VMFS-экстенты).
Частично это может помочь, однако управлять размещением ВМ по разным лунам нельзя, так как каждый хост “старается писать” в свою область данных на растянутом VMFS-разделе.
Рекомендации
Начиная эту статью, я хотел яростно обругать NFS-хранилища и сказать, что место им в SoHo.
Но, по большому счету, если вы:
- хотите использовать одно хранилище, а не несколько;
- размер единого хранилища ВМ превышает 62ТБ;
- не нуждаетесь в Raw Device Mapping;
- развернули Ethernet 10G (а лучше больше).
То вам может подойти NFS. Рекомендую иметь NFS с поддержкой VAAI.
Бонусом получите экономию на отсутствии у вас FC-инфраструктуры.
Если же вы хотите остаться на VMFS, то у меня есть ряд общих рекомендаций:
- количество хранилищ должно быть кратно количеству контроллеров вашего массива. Он может быть “ALUA” – и тогда обслуживает половину LUN только один контроллер с его кэшем. Еще лучше, если количество LUN кратно количеству путей до СХД;
- ВМ должны быть сбалансированы по этим хранилищам;
- тип балансировки доступа до хранилища должен быть приведен в соответствие с рекомендациями вендора. Скорее всего, это будет Round Robin, возможно, с переключением путей на каждый 1 iops;
- лучше использовать наиболее свежую версию vSphere и VMFS. Помимо явных упоминаний могут быть и улучшения, о которых VMware промолчало (например, в каком-то гайде производительности я встречал упоминание о том, что “пенальти” гипервизора на свежих процессорах и vSphere 6.x в два раза ниже, чем на более старых и vSphere 5.x);
- также лучше использовать наиболее свежее железо (касается хоста, СХД и коммутации). СХД лучше с поддержкой VAAI;
- желательно изредка анализировать ввод-вывод на VMFS-разделы. Если туда прилетает несколько тысяч IOPS, возможно, проклятие SCSI-очередей тут как тут.
Как в принципе избавиться от этого:
- VVol.
Дополнительные материалы:
P.S. Коллеги, приглашаю Вас высказать своё мнение в комментариях, поделиться своим опытом.
Получилось сумбурно и без реального сравнения, да и смысла в нём не так много, потому что NFS для VMware = NetApp.
> До появления vSphere 6.0 и NFS 4.1 единственным вариантом балансировки нагрузки являлся EtherChannel/LACP
pNFS в ESXi до сих пор не появился, так что балансировку по прежнему надо делать на уровне датасторов, вольюмов и сокетов:
https://cormachogan.com/2018/12/12/nfs-tcp-connections-on-vsphere-revisited/
Впрочем, сам FAS/AFF тоже не выдаст всю производительность на один FlexVol и без VVols тут не обойтись.
Про глубину очереди 32 странно. Вот тут https://kb.vmware.com/s/article/1267 сама Варя говорит, что значения по умолчанию зависят в том числе от производителя HBA и версии ESXi, но ни что не мешает поменять значение Query Depth per LUN на максимальное 64, если у вас только одна виртуалка использует датастор. Т.е. и отличий между разными HBA в общем то нет. А так же для датасторов, которые используются несколькими виртуальными машинами, есть вот эта статья https://kb.vmware.com/s/article/1268. И там максимальная Query Depth уже 256, а для ESXi 6.5 зависит фактически того что может принять СХД и LUN.
Про количество LUN кратное количеству путей и вовсе непонятная рекомендация. Во первых откуда она взялась? Это NetApp для своих СХД рекомендует? Во вторых какие именно пути имеются в виду? Физические от хоста до SAN, физические от СХД до SAN, а может и вовсе логические?
Если уж упомянули про RR и отправке каждого IOPS в новый путь можно было и ссылку привести на оригинал https://kb.vmware.com/s/article/2069356. И еще указать, что это хоть и увеличивает производительность в IOPS, но в то же время слегка поднимает и Latency.
А еще для тех, кто все таки выберет iSCSI, а не FC или NFS есть вот эта вот напоминалка https://kb.vmware.com/s/article/1002598. Ну и не забывать про jumbo frames на всем пути следования IO.
При использовании NFS и нормальных СХД, которые не теряют кэш при отключении электропитания, можно смотреть в сторону использования ассинхронной записи. И не забывать про возможность настраивать размер блока ввода/вывода те же jumbo frames. Подробнее можно почитать например тут http://www.admin-magazine.com/HPC/Articles/Useful-NFS-Options-for-Tuning-and-Management
Что касается vvol, то я бы пока не ставил их в продуктив. Концепция и идея интересная, но как по мне так тонким местом является необходимость в VASA провайдере, без которого ни чего не работает. А еще я пока не видел на рынке решений по построению metro конфигураций для vvol датасторов. Может я конечно и пропустил что-то и кто-то это уже реализовал. В конце концов обычная репликация для vvol вроде как начала появляться.
В одном вы правы. Ситуации, задачи и возможности у всех разные, а значит в каждом конкретном случае нужно смотреть, что и как целесообразнее применять.
Ximik, спасибо за подробный комментарий.
Менять глубину очереди до луна не рекомендуется без расчетов, так как глубина очереди на массиве (глубина очереди луна и контроллера) также конечна.
https://cms.vmworldonline.com/event_data/5/session_notes_eu/SER2355BE.pdf
К примеру, если у вас задержка от массива 6мс (SAS10k), то с глубиной очереди 32 вы можете получить до 5 тысяч IOPS на один LUN и один хост:
1000ms/6ms=166 IOPS
166 iops * 32 outstanding IOs = 5312 IOPS
Я думаю, что эти ограничения (lun queue=32) и (hba queue<=256++) были введены для того, чтобы нельзя было с одного хоста "перегрузить" СХД. "Пути СХД": подразумевается количество портов ввода-вывода на обоих контроллерах СХД. Например, MSA 2050/EVA6000/3PAR7200 - 4 порта ввода-вывода. Рекомендация иметь кратное путям количество лунов продиктована тем, что: 1) В ALUA-массивах два контроллера, запросы к LUN обрабатываются на одном из них. Соответственно, чтобы задействовать оба - вам нужно минимум два LUN. 2) Очередь на LUN изнутри массива меньше очереди контроллера. Сделав несколько LUN для каждого контроллера вы, возможно, не упретесь в эту очередь на LUN со стороны СХД. Рекомендация иметь количество LUN кратным количеству портов ввода-вывода СХД основывается на ALUA-архитектуре и взята из личного опыта.
A.Vakhitov, с вашим комментарием уже понятнее. Но то, что касается глубины очередей на СХД, то они там в достаточной степени велики. На один порт IO глубина может составлять 1,5-2к (зависит от производителя). И даже в так называемом midrange сегменте есть СХД, где на каждый контроллер может приходиться от одного до нескольких десятков портов.
Вот про сами луны уже интереснее, там все сильно зависит от количества HDD или SSD по которым LUN размазан. Но и это в принципе, как вы и написали, считается и значения там тоже могут достигать вполне себе больших величин.
Сходная рекомендация (2x-3x VMFS-томов на количество путей) есть в этой презентации с VMWorld.
https://cms.vmworldonline.com/event_data/5/session_notes/STO2115BUR.pdf
Шли годы… десятилетия… а в рунете все выясняли, можно ли использовать NFS для хранилищ VMware. Этак лет через пять вы доберетесь до ключевого вопроса – можно ли в enterprise использовать iSCSI, или стоит все же еще лет пять подождать , слишком какое-то молодое изобретение.
Какие люди 🙂