Disclaimer: статья основана на следующих источниках:
- What’s New in vSphere 8?
- VMware vSphere 8 – What’s new?
- Lifecycle Management Made Simple with vSphere Lifecycle Manager
- Extreme Performance Series: vSphere Advanced Performance Tutorial
- Introducing vSphere 8: The Enterprise Workload Platform
- 10 New and Exciting Things About vSphere 8 That You Absolutely Need to Know
VMware vSphere 8 – это платформа для корпоративных рабочих нагрузок, которая обеспечивает преимущества облачных вычислений для локальных рабочих нагрузок. Она повышает производительность благодаря ускорению на базе DPU и GPU, улучшает операционную эффективность с помощью VMware Cloud Console, легко интегрируется с дополнительными гибридными облачными службами и ускоряет инновации благодаря интегрированной среде выполнения Kubernetes корпоративного уровня, позволяющей запускать контейнеры вместе с ВМ.
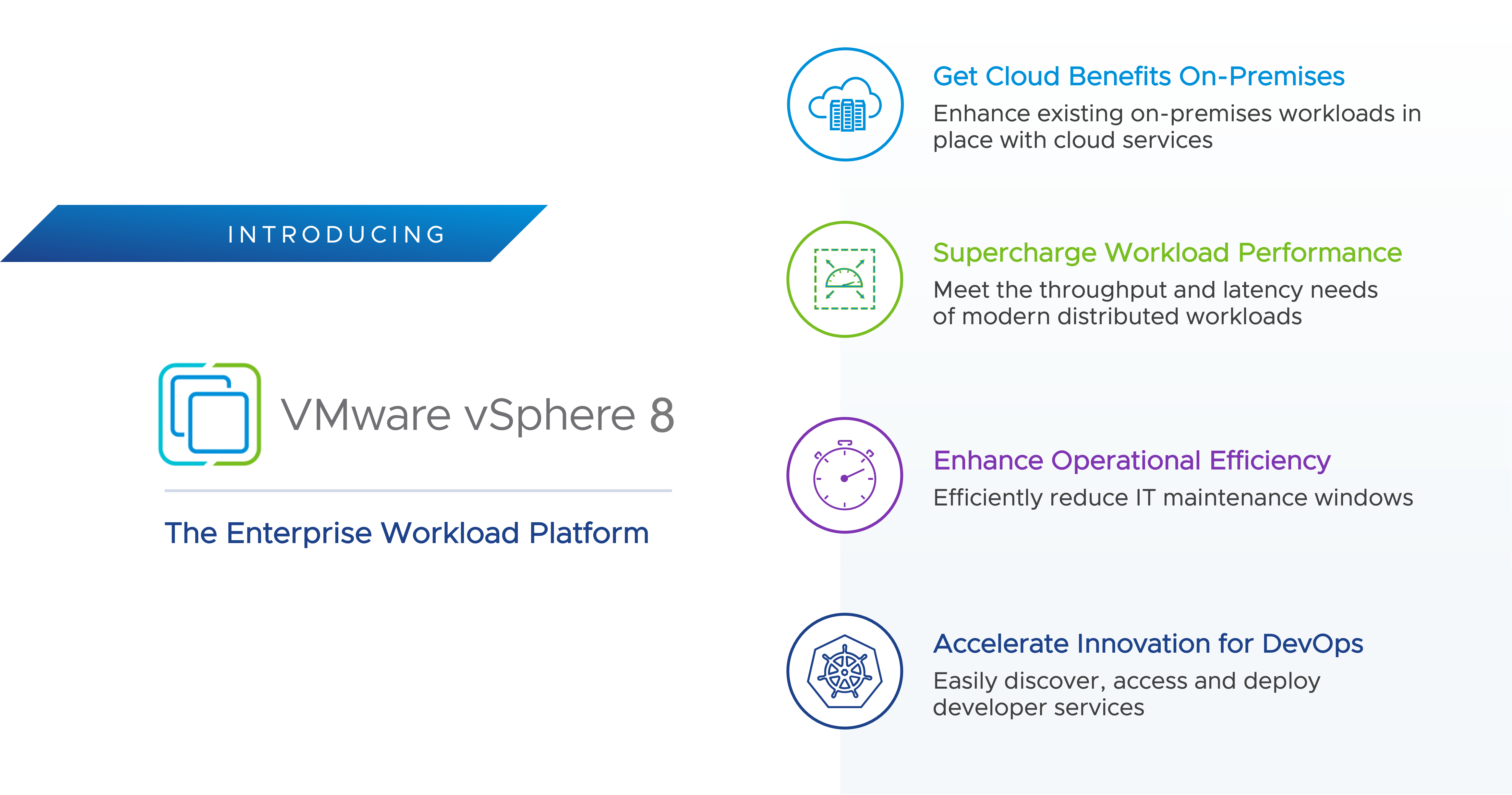 vSphere 8 Intro
vSphere 8 Intro
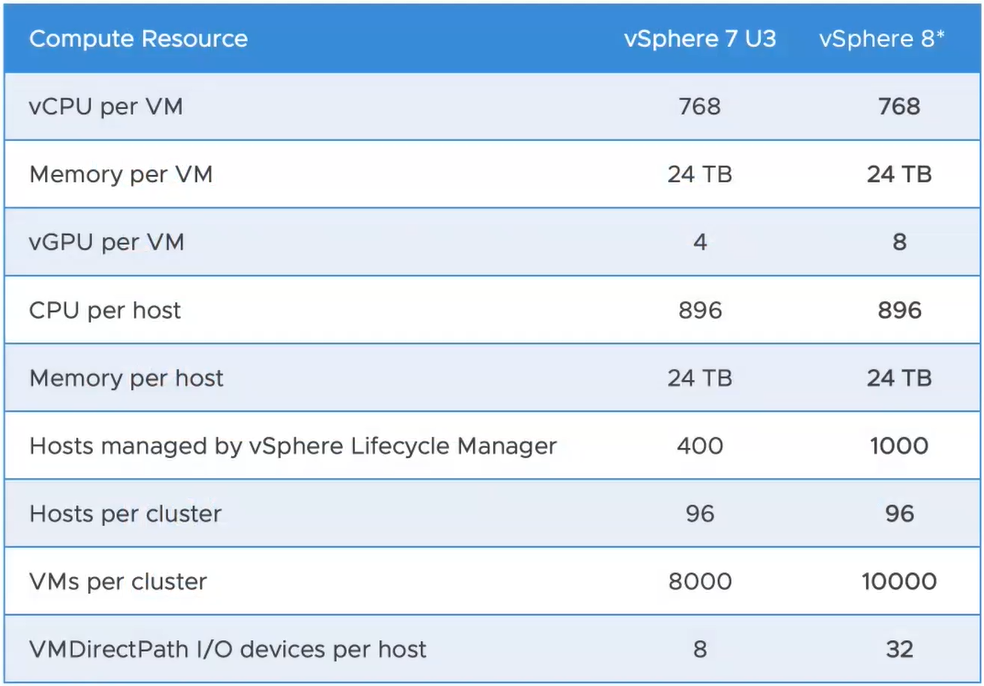 Config Maximum
Config Maximum
vSphere Distributed Services Engine
Представляем vSphere Distributed Services Engine, ранее называвшийся Project Monterey. vSphere Distributed Services Engine раскрывает возможности блоков обработки данных (DPU) для аппаратно-ускоренной обработки данных для повышения производительности инфраструктуры, повышения безопасности инфраструктуры и упрощения управления жизненным циклом DPU. vSphere 8 упрощает использование DPU для рабочих нагрузок, чтобы воспользоваться этими преимуществами.
Появление блока обработки данных DPU
Блоки обработки данных (DPU) существуют уже сегодня и находятся на аппаратном уровне, подобно устройствам PCIe, таким как сетевая карта или GPU. Сегодня службы управления сетями, хранилищами и хостами работают в экземпляре ESXi, виртуализирующем вычислительный уровень x86.
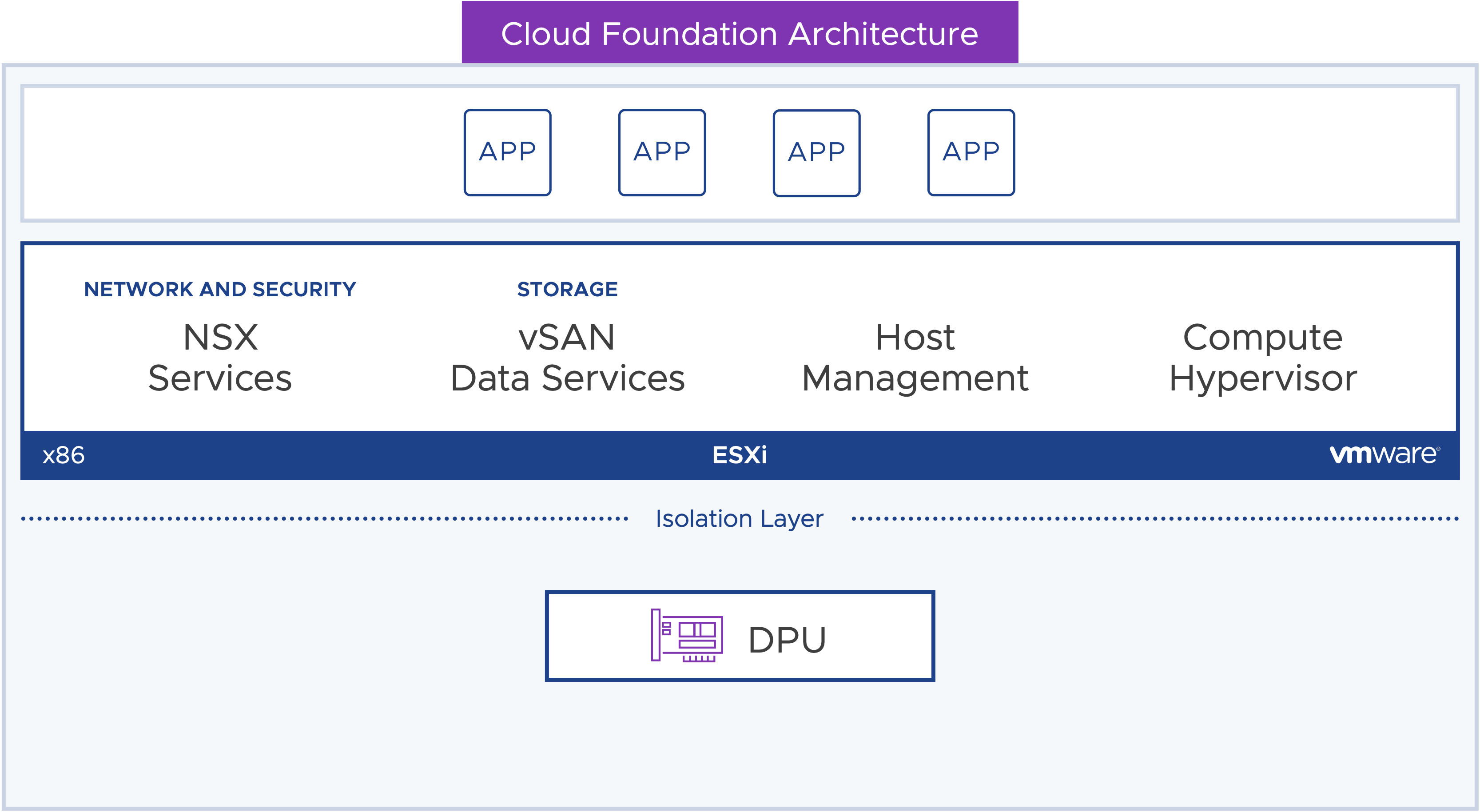 ESXi на DPU
ESXi на DPU
Подробнее о блоках обработки данных DPU – The rise of DPUs in the Infrastructure.
Знакомство с vSphere Distributed Services Engine
В vSphere 8 дополнительный экземпляр ESXi устанавливается непосредственно на блок обработки данных. Это позволяет разгрузить службы ESXi на DPU для повышения производительности.
В vSphere 8 мы поддерживаем установку “с чистого листа” с поддержкой разгрузки сети с помощью NSX. vSphere Distributed Services Engine управляется в течение жизненного цикла с помощью vSphere Lifecycle Manager. При восстановлении хоста, содержащего установку DPU ESXi, версия DPU ESXi всегда восстанавливается вместе с родительским хостом и поддерживается в соответствии с версией.
 ESXi на DPU
ESXi на DPU
Простая конфигурация для разгрузки сети
Используя vSphere Distributed Switch версии 8.0 и NSX, сетевые службы перегружаются на DPU, что позволяет повысить производительность сети без накладных расходов на процессор x86, улучшить видимость сетевого трафика, а также обеспечить безопасность, изоляцию и защиту, которые вы ожидаете от NSX.
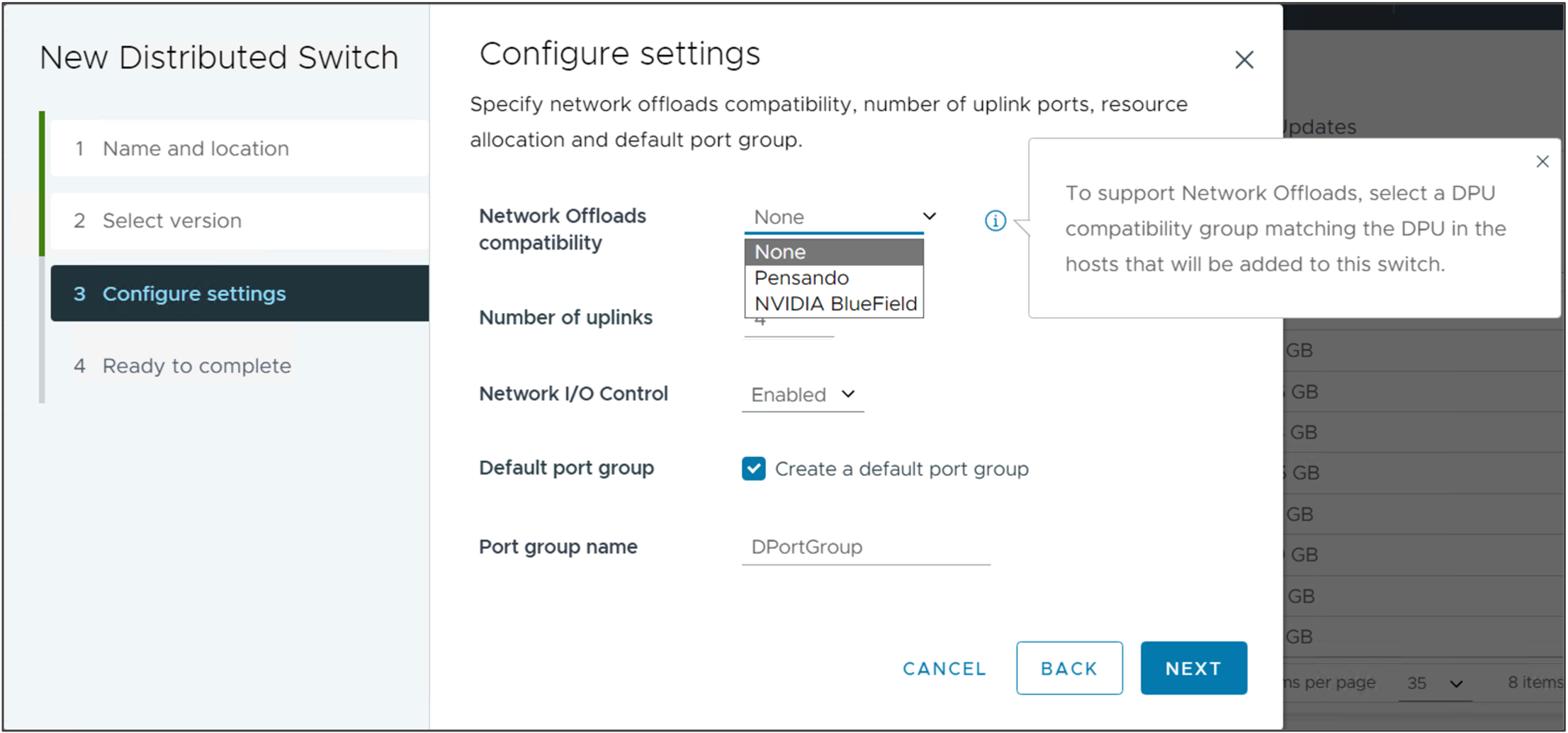 DPU на VDS
DPU на VDS
vSphere с Tanzu
Tanzu Kubernetes Grid на vSphere 8 объединяет предложения Tanzu Kubernetes в единую унифицированную среду выполнения Kubernetes от VMware.
Зоны доступности рабочей нагрузки (Workload Availability Zones) используются для изоляции рабочих нагрузок между кластерами vSphere. Кластеры супервизоров и кластеры Tanzu Kubernetes могут быть развернуты в зонах для повышения доступности кластеров путем обеспечения того, чтобы узлы не использовали одни и те же кластеры vSphere.
ClusterClass – это способ декларативно указать конфигурацию кластера через проект с открытым исходным кодом ClusterAPI.
Базовые образы PhotonOS и Ubuntu могут быть настроены и сохранены в библиотеке контента для использования в кластерах Tanzu Kubernetes.
Интеграция Pinniped поставляется в кластеры супервизора и кластеры Tanzu Kubernetes. Pinniped поддерживает федеративную аутентификацию LDAP и OIDC. Вы можете определить поставщиков идентификационных данных, которые могут использоваться для аутентификации пользователей на кластерах супервизора и кластерах Tanzu Kubernetes.
Повышение устойчивости рабочей нагрузки в современных приложениях
Зоны доступности рабочей нагрузки позволяют кластерам супервизоров и кластерам Tanzu Kubernetes охватывать кластеры vSphere для повышения доступности. Пространства имен vSphere охватывают зоны доступности рабочей нагрузки для поддержки развертывания кластеров Tanzu Kubernetes для повышения доступности в разных зонах.
 Зоны доступности рабочей нагрузки
Зоны доступности рабочей нагрузки
Для обеспечения доступности необходимы три зоны доступности рабочей нагрузки. Во время активации Управления рабочей нагрузки (Workload Management) у вас есть выбор между развертыванием в зоны доступности рабочей нагрузки (Workload Availability Zones) и развертыванием в одном кластере. В vSphere 8 GA зона доступности рабочей нагрузки имеет соотношение 1:1 с кластером vSphere.
Определите один раз, используйте много раз
ClusterClass предоставляет декларативный способ определения конфигурации кластера Tanzu Kubernetes, а также установленных по умолчанию пакетов. Команда разработчиков платформы может определить пакеты инфраструктуры, которые должны быть установлены при создании кластера. Это могут быть сетевые провайдеры, хранилища или облачные провайдеры, а также механизм аутентификации и сбор метрик. Спецификация кластера ссылается на ClusterClass.
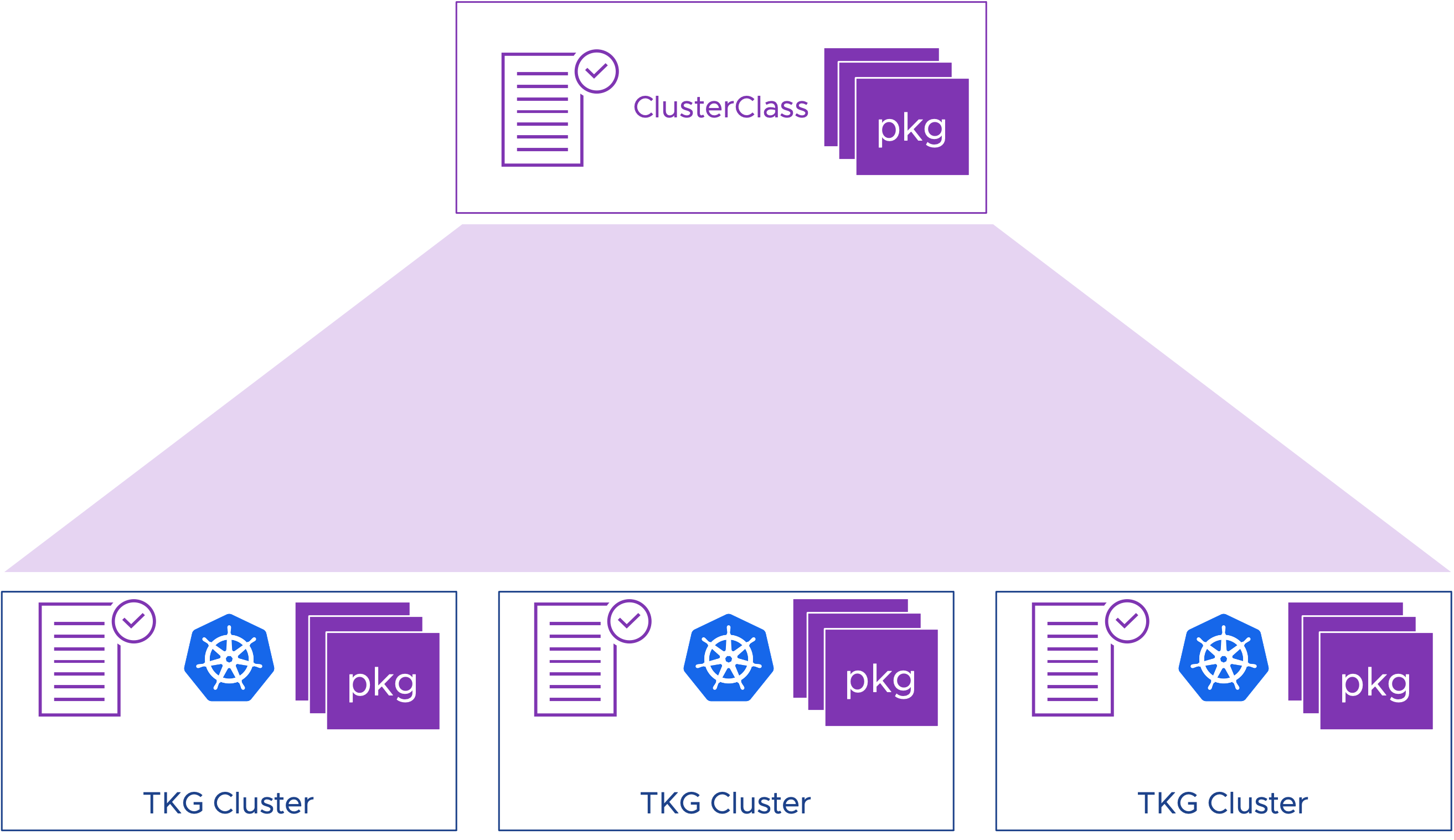 API ClusterClass
API ClusterClass
ClusterClass – это спецификация с открытым исходным кодом, которая является частью проекта ClusterAPI. ClusterAPI определяет декларативный способ управления жизненным циклом кластеров Kubernetes через существующий управляющий кластер Kubernetes. В vSphere с Tanzu таким управляющим кластером является кластер супервизора.
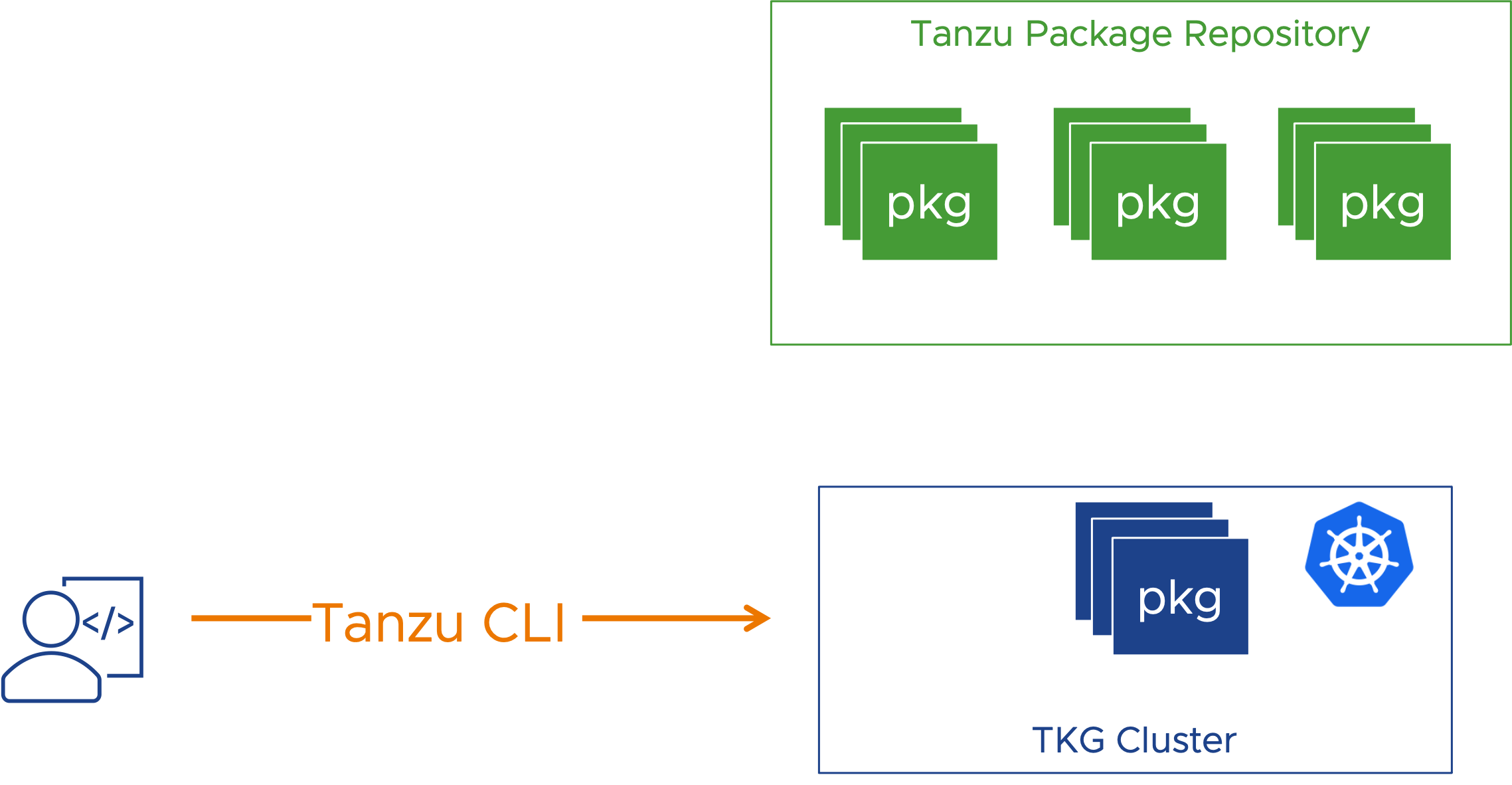
Гибкое управление пакетами
После развертывания кластера разработчики или пользователи DevOps могут по желанию добавлять дополнительные пакеты из репозитория стандартных пакетов Tanzu. Эти пакеты могут включать Contour для входа в кластер, управление сертификатами, ведение журналов, наблюдаемость с помощью Prometheus или Grafana или внешний DNS. Они управляются как дополнения через интерфейс Tanzu CLI.
Привлечение собственного поставщика идентификационных данных
В vSphere 7 аутентификация выполняется посредством интеграции с vCenter Single Sign-On. Вы можете продолжать использовать vCenter Single Sign-On в vSphere 8, но у вас также есть альтернатива. Используя интеграцию Pinniped, кластер супервизора и кластеры Tanzu Kubernetes могут иметь прямой доступ OIDC или LDAP к поставщику идентификационных данных ( Identity Provider, IDP), не полагаясь на vCenter Single Sign-On. Для облегчения интеграции на кластере супервизора и кластерах Tanzu Kubernetes автоматически развертываются подсистемы Pinniped.
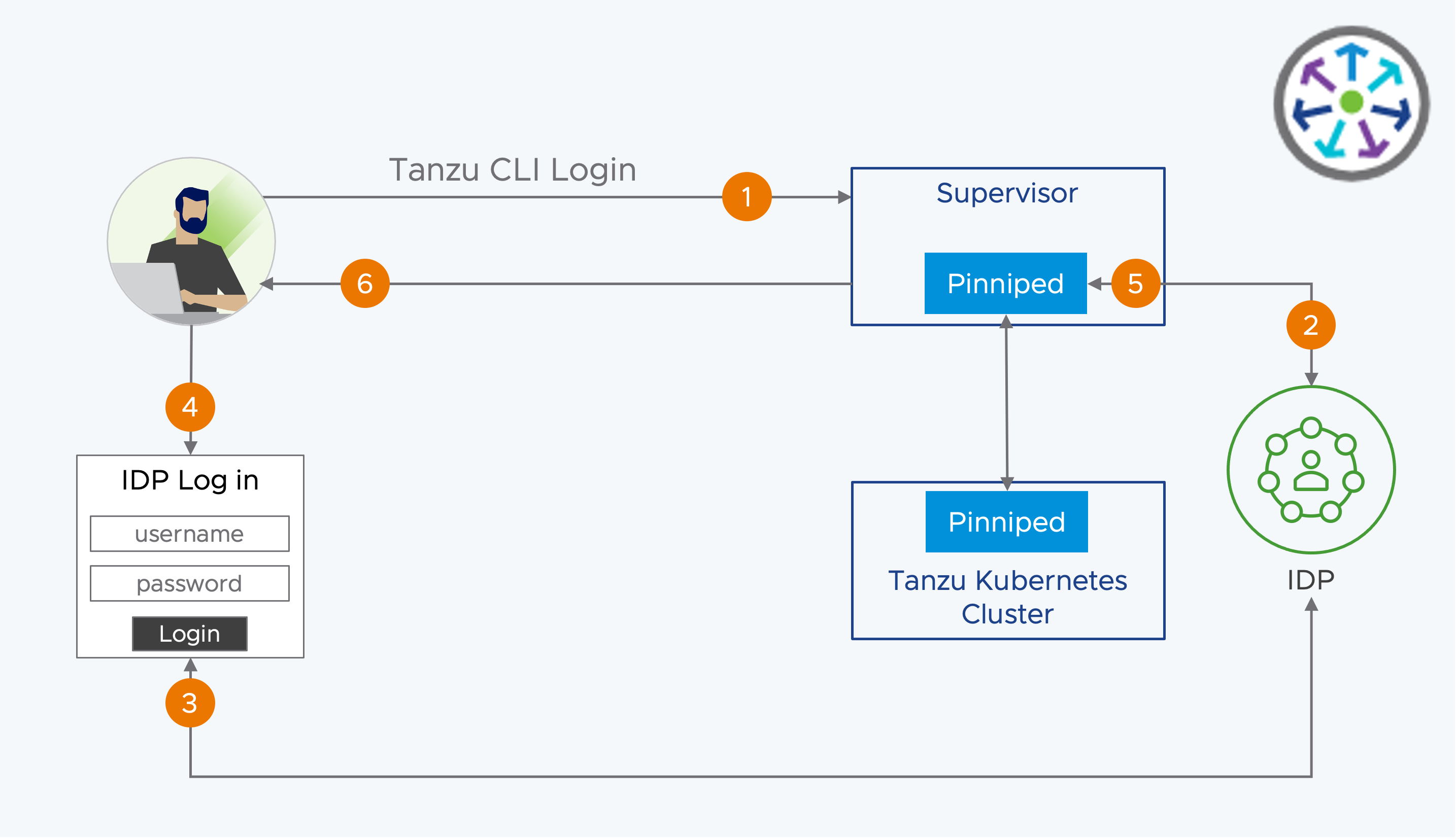 Интеграция Pinniped
Интеграция Pinniped
- Пользователь DevOps использует логин Tanzu CLI для аутентификации на супервизоре и/или TKC.
- Интеграция Pinniped подключается к IDP
- IDP возвращает ссылку или окно для входа
- Пользователь DevOps предоставляет учетные данные IDP
- Успешная аутентификация на IDP возвращается в Pinniped
- Tanzu CLI создает файл kubeconfig, необходимый для доступа к Supervisor и/или TKC.
Управление жизненным циклом
В vSphere 8 появилась поддержка DPU для vSphere Lifecycle Manager для автоматического обновления установки ESXi на DPU в соответствии с версией ESXi на хосте. Предустановка (staging) обновлений/новых версия, параллельный накат обновлений(remediation) и поддержка одиночных хостов позволяют довести vLCM до функционального паритета с Update Manager. Одиночными хостами можно управлять с помощью vSphere Lifecycle Manager через API. В руководстве по совместимости VMware подробно описано, какие функции vLCM может поддерживать менеджер поддержки оборудования (Hardware Support Manager).
Предварительная версия vSphere Configuration Profiles представляет следующее поколение управления конфигурацией кластера в качестве будущей замены Host Profiles.
Информирование об устаревании
Управление жизненным циклом через создание базовых линий (Baseline), ранее известное как vSphere Update Manager, в vSphere 8 устарело. Это означает, что старое управление жизненным циклом все еще поддерживается в vSphere 8, но vSphere 8 станет последним выпуском с такой поддержкой.
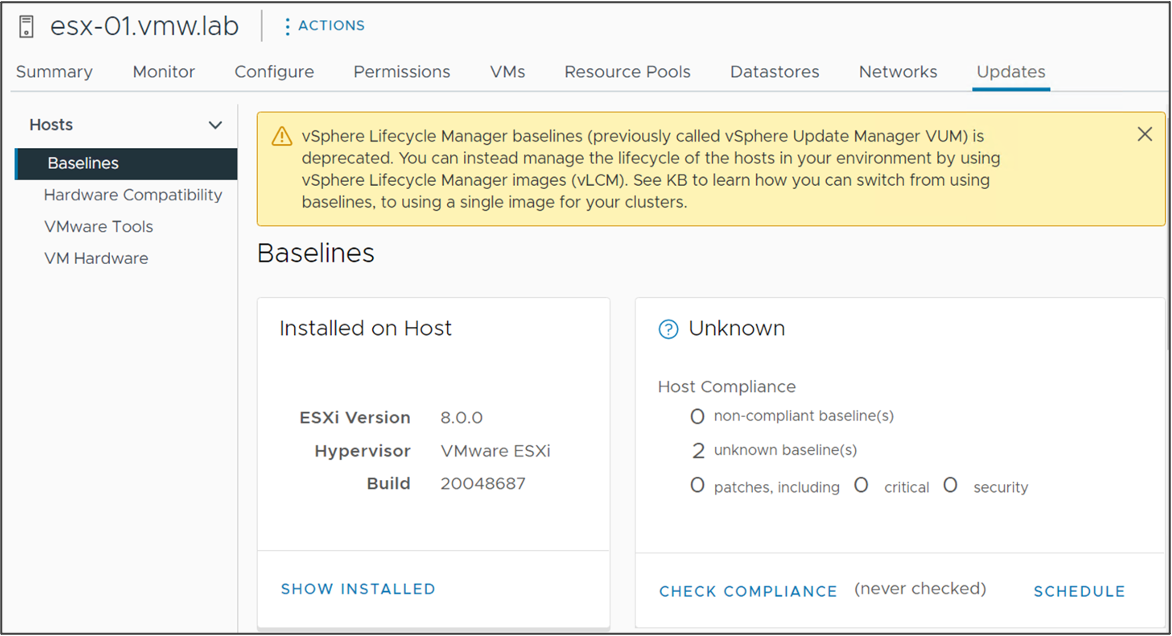 Исчезновение базовой линии
Исчезновение базовой линии
Предустановка нового образа кластера для ускорения наката обновлений
vSphere Lifecycle Manager может предустановить обновления на хосты до начала наката обновлений. Предустановка может быть выполнена без режима обслуживания. Это сокращает время пребывания узлов в режиме обслуживания. Прошивки также может быть предустановлены через интеграцию от поддерживаемого диспетчера поддержки оборудования.
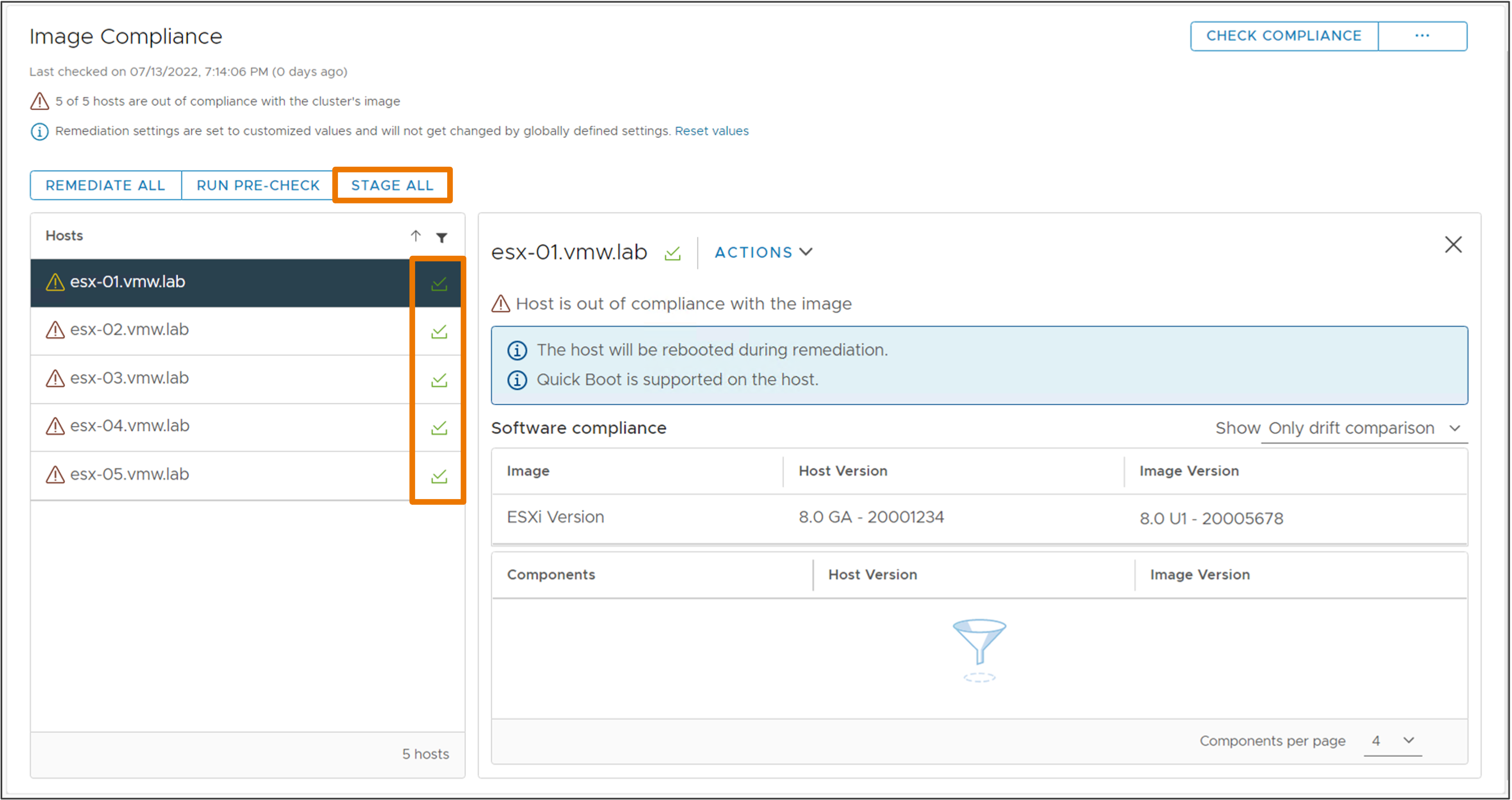 Поэтапные обновления
Поэтапные обновления
Быстрый накат обновлений в кластере
vSphere Lifecycle Manager теперь может накатывать обновления на несколько хостов параллельно, значительно сокращая общее время, необходимое для обновления всего кластера. Хосты, переведенные в режим обслуживания, можно обновлять параллельно. Администратор vSphere может выбрать накат на все узлы в режиме обслуживания или определить количество параллельных накатов, которые необходимо выполнить в определенное время. Хосты, не переведенные в режим обслуживания, не обновляются во время этой операции жизненного цикла.
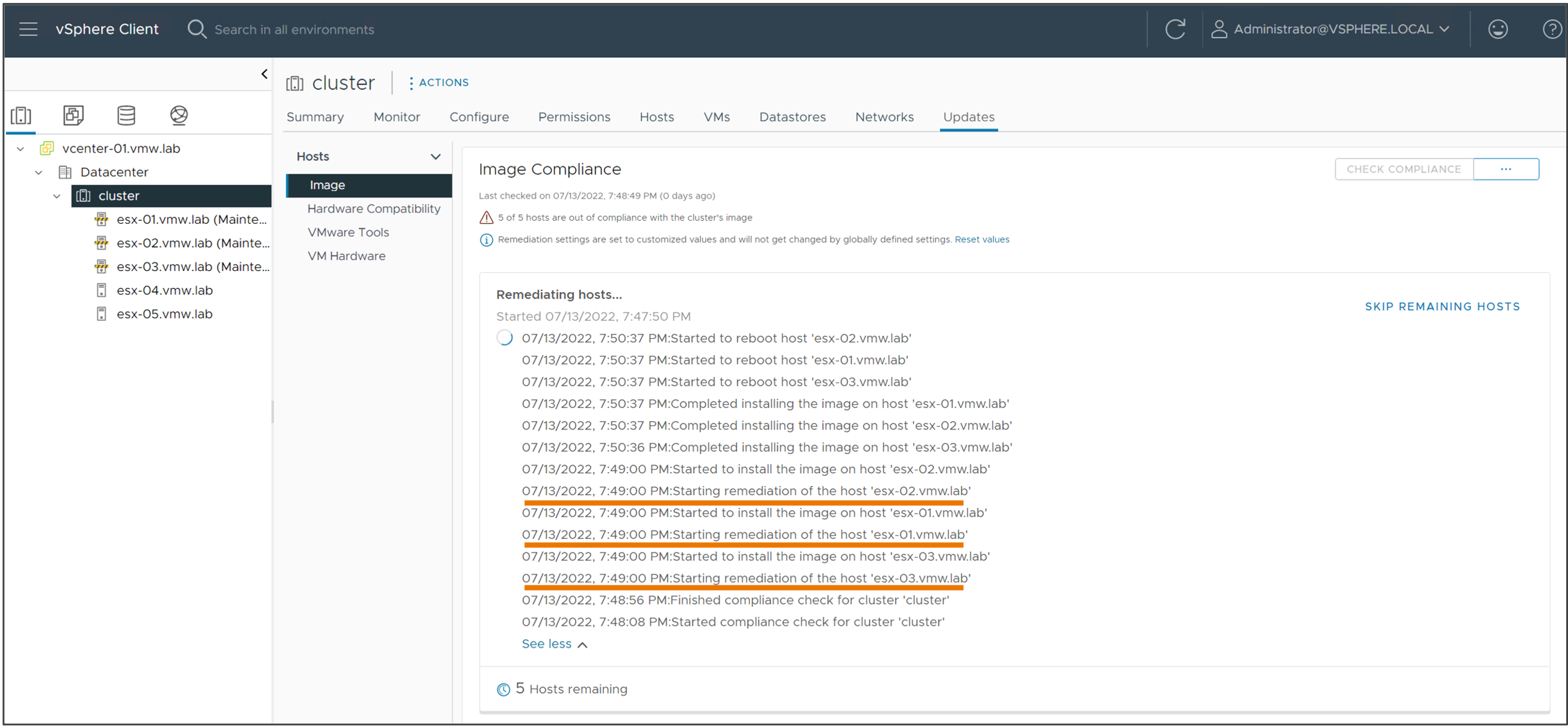 Параллельный накат обновлений
Параллельный накат обновлений
Управление конфигурацией
В vSphere 8 представлена предварительная версия vSphere Configuration Profiles (конфигурационные профили), нового поколения управления конфигурацией кластера.
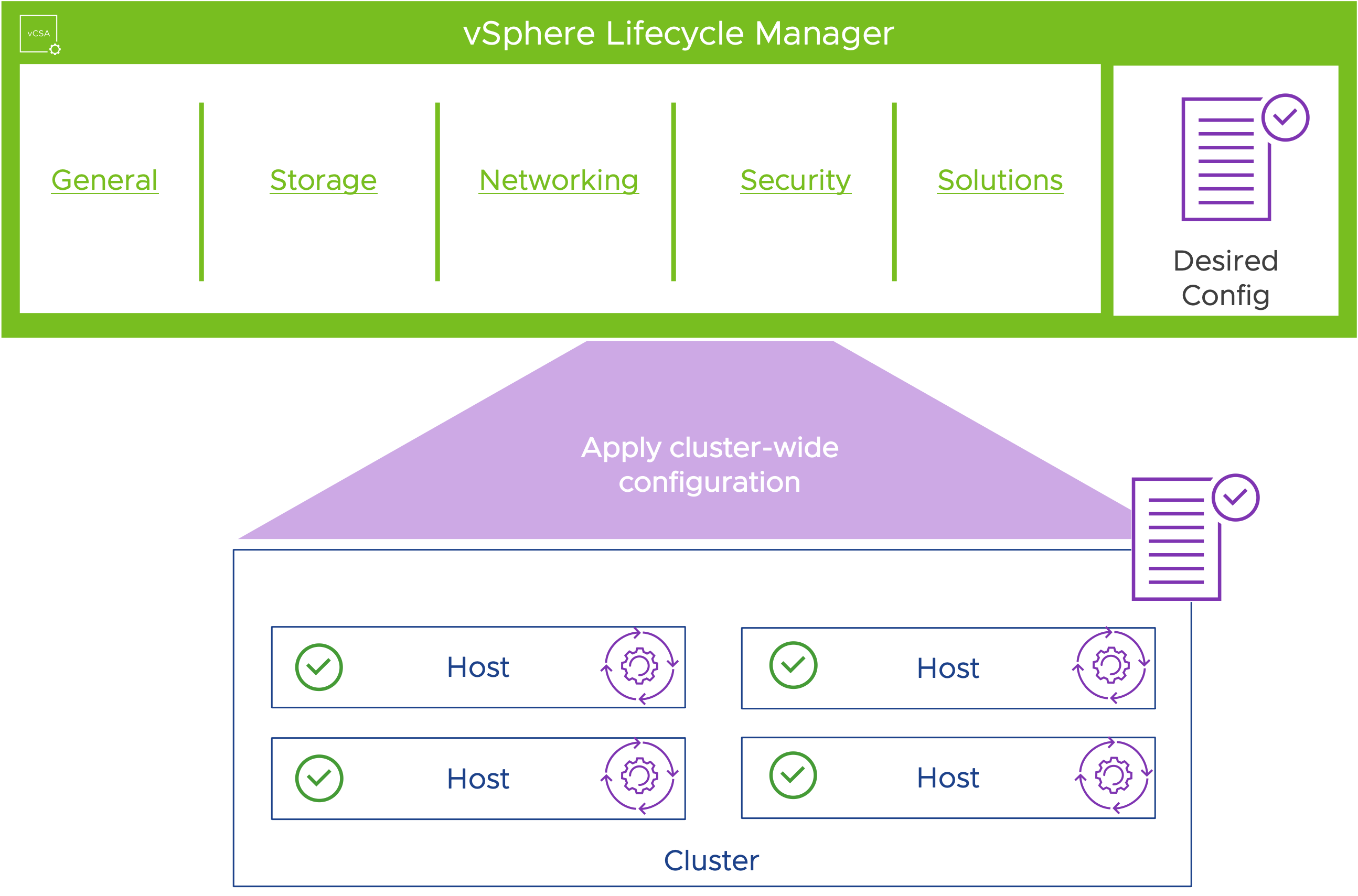 Профили конфигурации
Профили конфигурации
Желаемая конфигурация определяется на объекте кластера и применяется ко всем хостам в кластере. На всех узлах кластера применяется консистентная конфигурация. Дрейф конфигурации отслеживается и о нем сообщается. Администратор vSphere может устранить дрейф конфигурации.
vSphere Configuration Profiles находятся в стадии активной разработки, и в будущих выпусках vSphere 8 их поддержка будет расширена и улучшена. Профили хостов(Host Profiles) продолжают поддерживаться в vSphere 8.
Улучшенное восстановление vCenter
vCenter выравнивает состояние кластера после восстановления из резервной копии. Хосты ESXi в кластере содержат распределенное хранилище ключей-значений состояния кластера.
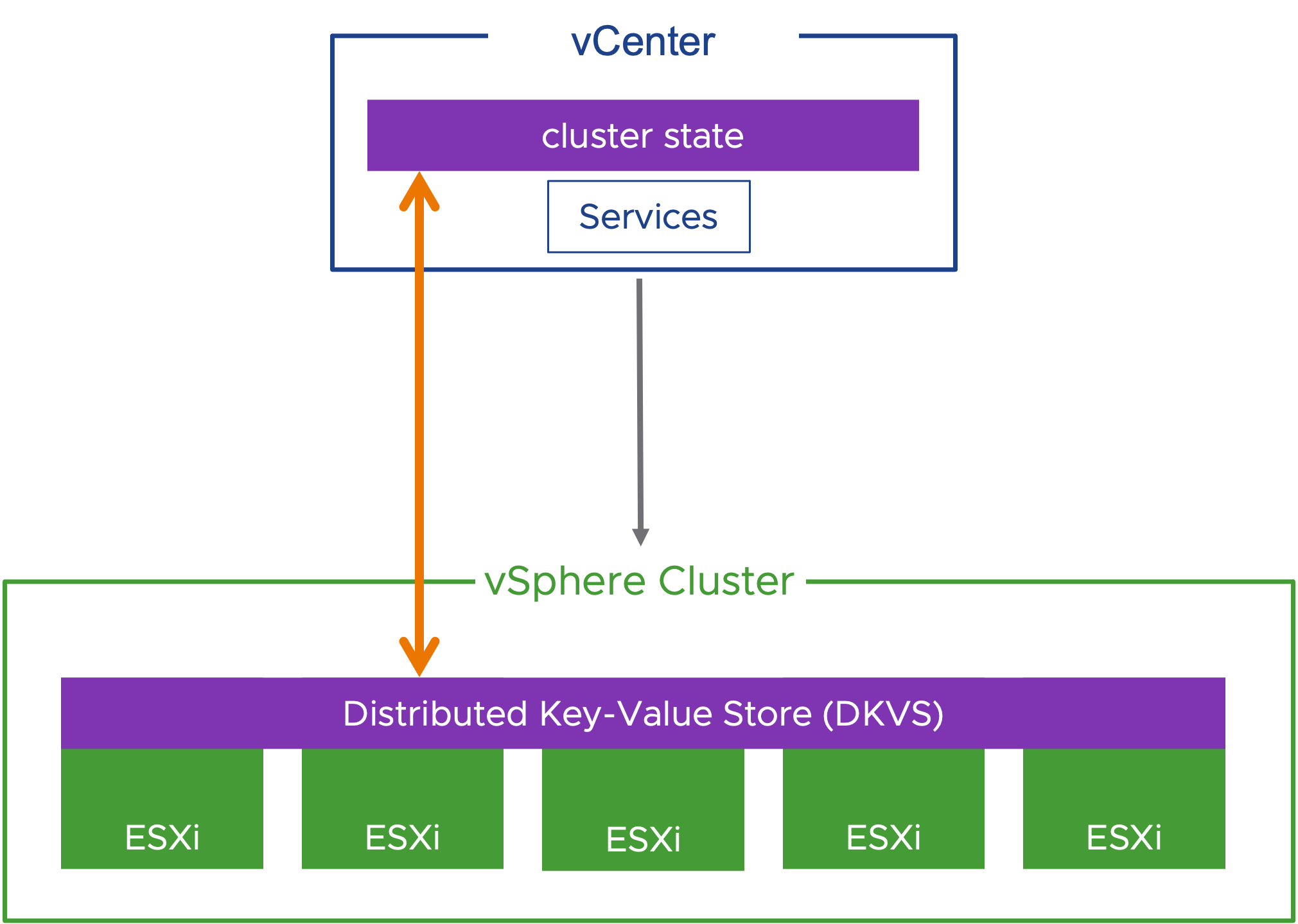 Кластерное хранилище ключевых значений
Кластерное хранилище ключевых значений
Распределенное хранилище ключевых значений является источником истины для состояния кластера. Если vCenter восстанавливается из резервной копии, он сверяет состояние и конфигурацию кластера с распределенным хранилищем ключевых значений. В vSphere 8 выверяется принадлежность хоста к кластеру, а в будущих выпусках планируется поддержка дополнительных конфигураций и состояний.
AI & ML (ИИ и МО)
Унифицированное управление аппаратными ускорителями AI/ML (ИИ/МО)
Device Groups (Группы устройств) упрощают работу виртуальных машин, использующих дополнительные аппаратные устройства, в vSphere 8. Устройства NIC и GPU поддерживаются в vSphere 8, но требуются драйверы совместимых устройств, которые будут выпущены производителем. NVIDIA® будет первым партнером, поддерживающим Группы устройств с выходом совместимых драйверов.
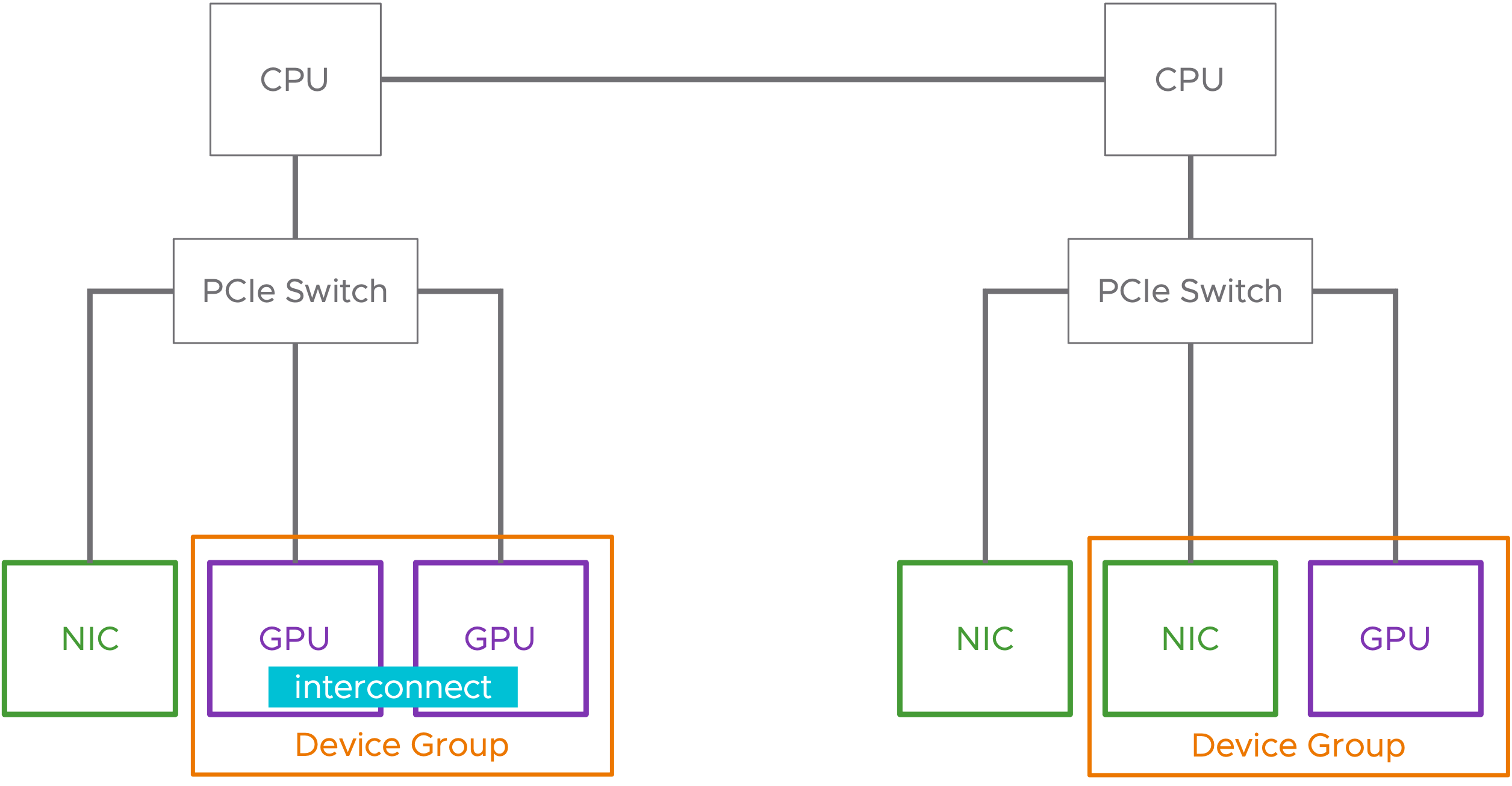 Группы устройств
Группы устройств
Группы устройств могут состоять из двух или более аппаратных устройств, которые имеют общий PCIe коммутатор или устройства, имеющие прямое межсоединение(interconnect) между собой. Группы устройств обнаруживаются на аппаратном уровне и представляются в vSphere как единое целое, представляющее группу.
Упрощенное использование аппаратного обеспечения с помощью Групп устройств
Группы устройств добавляются к виртуальным машинам с помощью существующих рабочих процессов Add New PCI Device. vSphere DRS и vSphere HA знают о Группах устройств и будут размещать виртуальные машины соответствующим образом, чтобы удовлетворить группу устройств.
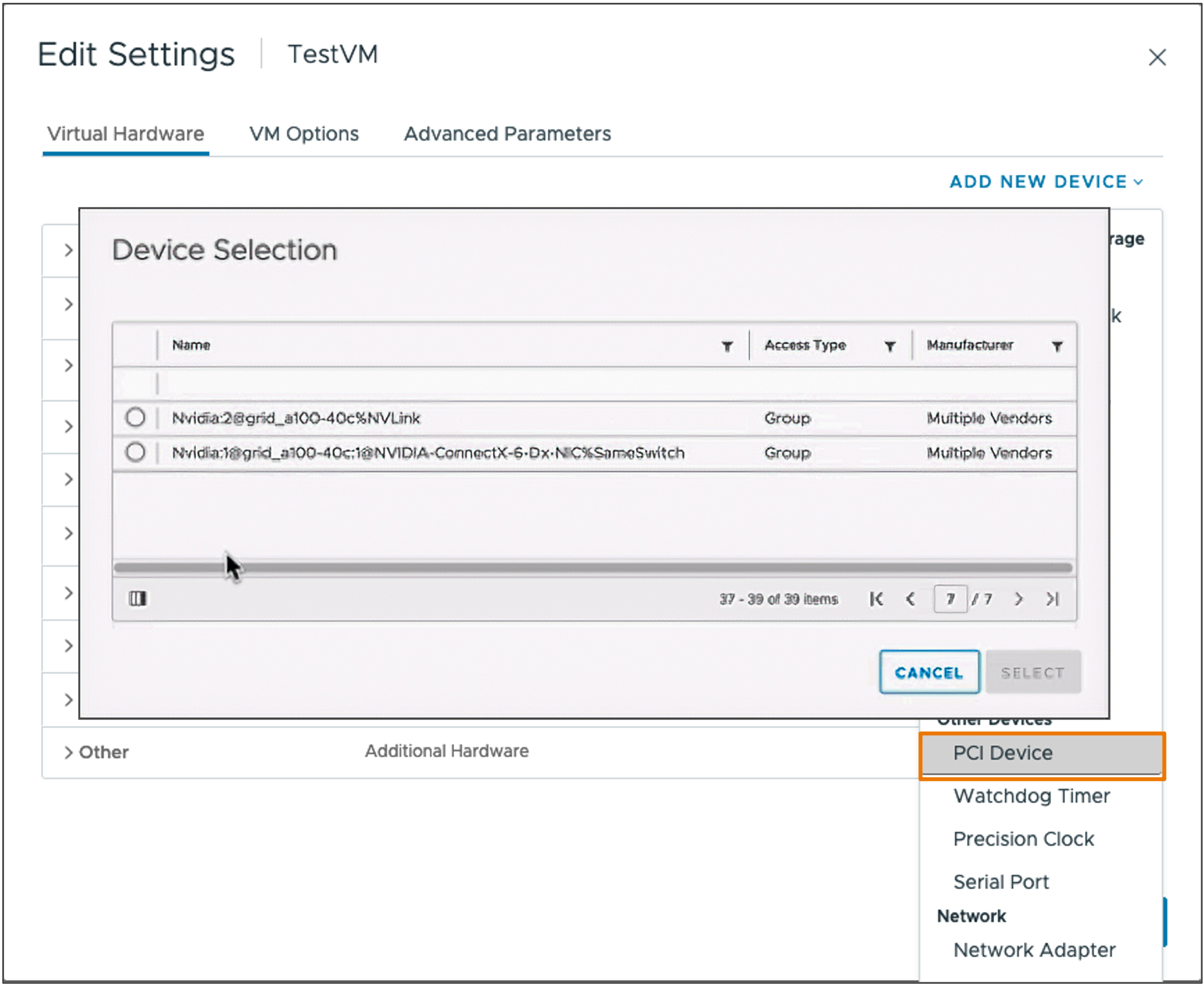 Добавление группы устройств
Добавление группы устройств
Виртуальные аппаратные устройства нового поколения
Device Virtualization Extensions(Расширения виртуализации устройств) основывается на Dynamic DirectPath I/O и представляет новую структуру и API для производителей для создания виртуальных устройств с аппаратной поддержкой. Device Virtualization Extensions позволяет расширить поддержку таких функций виртуализации, как живая миграция с помощью vSphere vMotion, приостановка и возобновление работы виртуальной машины, а также поддержка снимков диска и памяти.
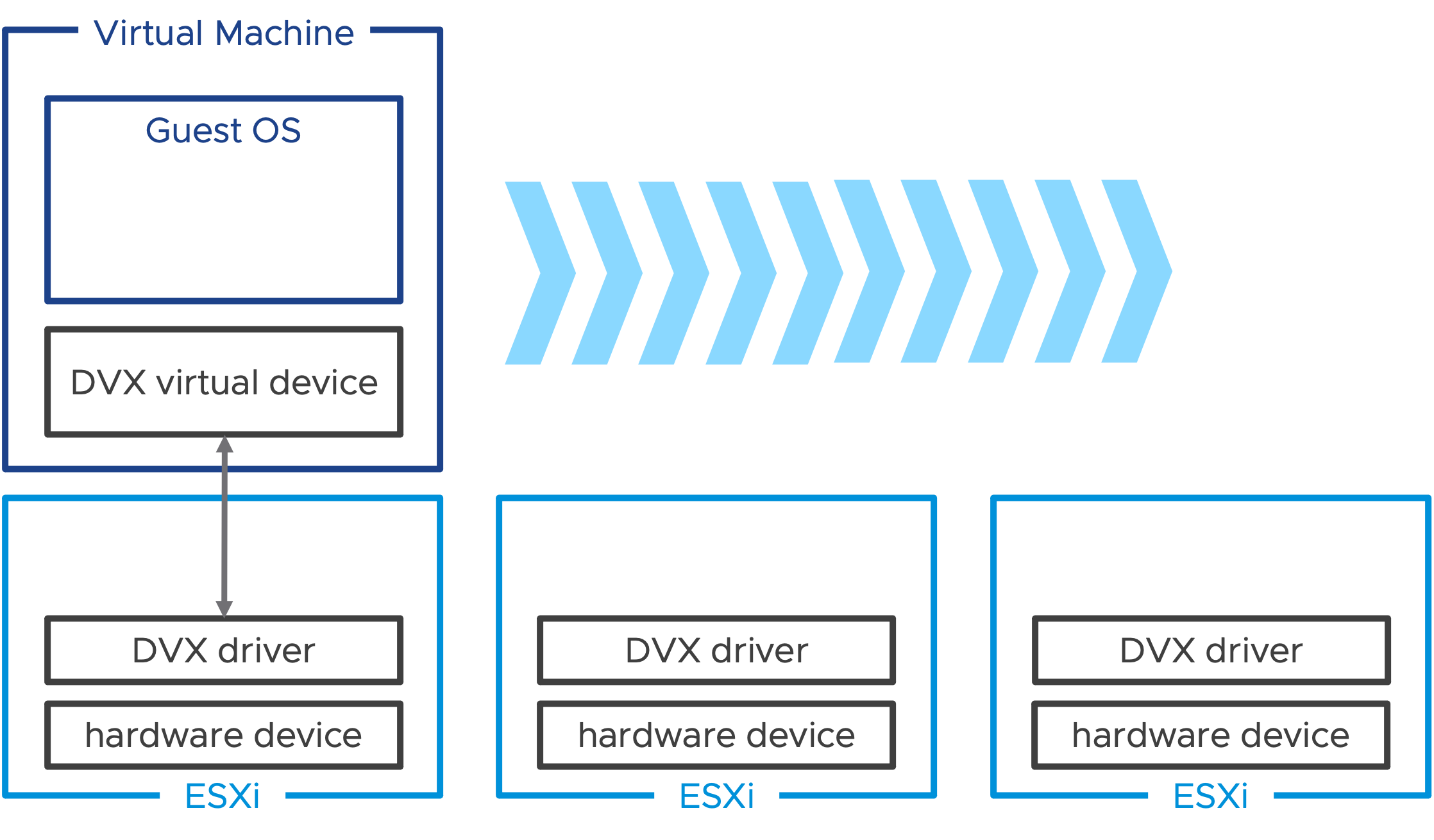 Расширения виртуализации устройств
Расширения виртуализации устройств
Совместимый драйвер должен быть установлен на хостах ESXi и сопровождаться соответствующим драйвером гостевой ОС для эквивалента виртуального устройства. Виртуальная машина, потребляющая виртуальное устройство расширения виртуализации устройств, может быть перемещена с помощью vSphere vMotion на другой хост, поддерживающий это же виртуальное устройство.
Гостевая ОС и рабочие нагрузки
Виртуальное оборудование vHW версии 20
Виртуальное оборудование версии 20 – это последняя версия виртуального оборудования, которая привносит новые инновации в виртуальное оборудование, улучшает гостевые службы для приложений, а также повышает производительность и масштабируемость для определенных рабочих нагрузок.
 vHW 20
vHW 20
Развертывание Windows 11
TPM Provision Policy – Windows 11 требует наличия устройств vTPM в виртуальных машинах. Клонирование виртуальной машины с vTPM может создать риск безопасности, поскольку секреты TPM клонируются.
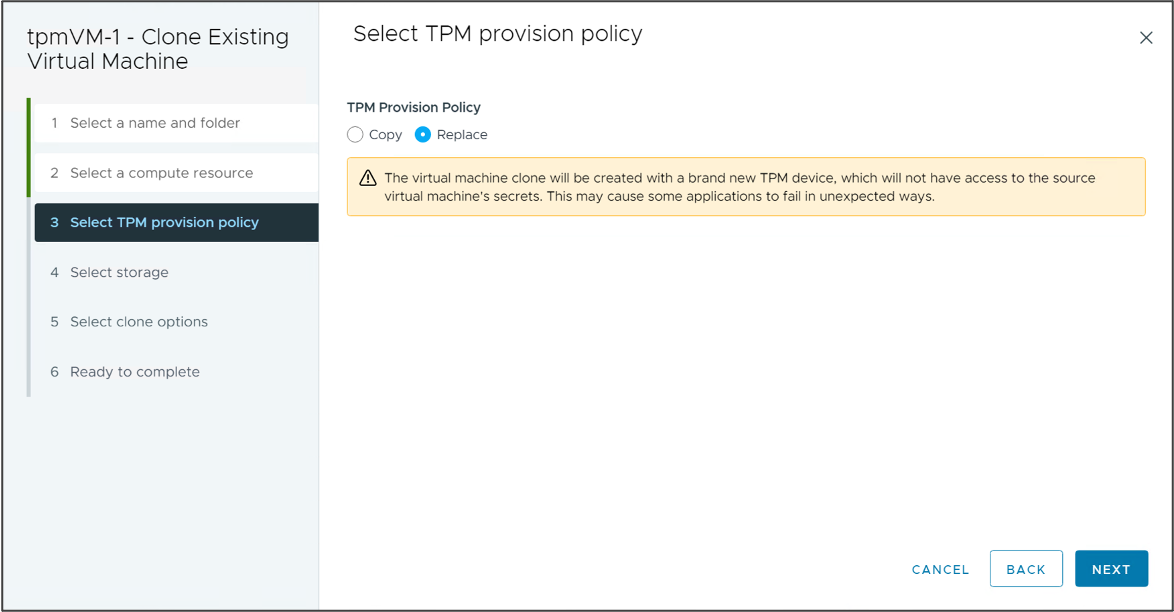 Политика распространения TPM
Политика распространения TPM
В vSphere 8 устройства vTPM могут быть автоматически заменены во время операций клонирования или развертывания. Это позволяет следовать лучшим практикам, согласно которым каждая ВМ содержит уникальное устройство TPM, и улучшает поддержку vSphere для развертывания Windows 11 в масштабе. vSphere 8.0 также включает расширенный параметр vpxd.clone.tpmProvisionPolicy, чтобы сделать поведение клонирования по умолчанию для vTPM заменяемым.
Сокращение перебоев в работе посредством подготовки приложения к миграции
Некоторые приложения не могут переносить остановки, связанные с vSphere vMotion. Эти приложения могут быть написаны с учетом миграции для улучшения их совместимости с vSphere vMotion. Приложения могут подготовиться к событию миграции. Это может быть постепенная остановка служб или выполнение обхода отказа в случае кластерного приложения. Приложение может отложить начало миграции до настроенного таймаута, но не может отказаться или предотвратить миграцию.
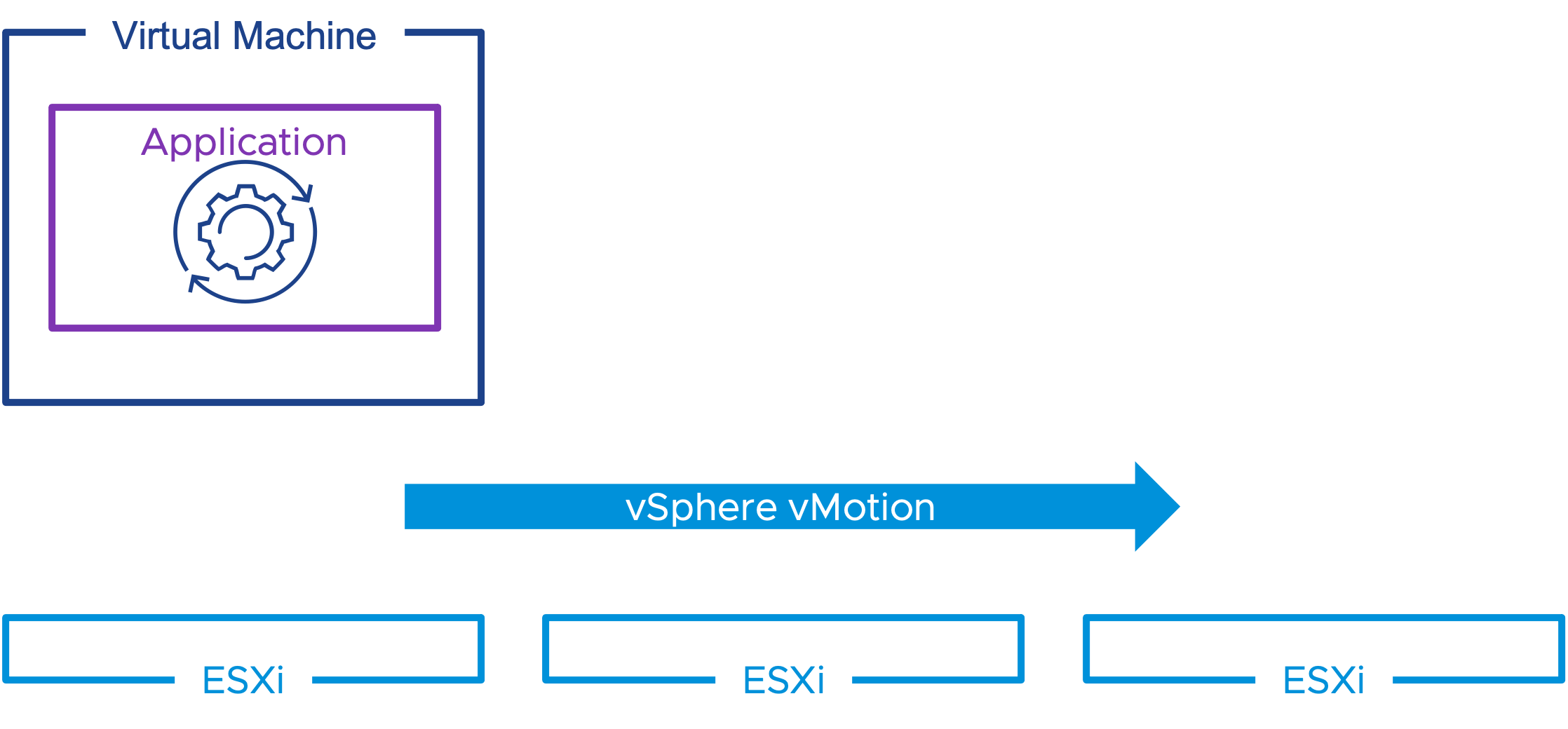 Миграция с учетом приложений
Миграция с учетом приложений
Примеры использования включают:
- чувствительные ко времени приложения;
- VoIP-приложения;
- кластерные приложения.
Максимизация производительности для рабочих нагрузок, чувствительных к задержкам
Новые рабочие нагрузки в телекоммуникационной отрасли требуют усиленной поддержки приложений, чувствительных к задержкам. Решение High Latency Sensitivity with Hyper-threading разработано для поддержки таких рабочих нагрузок и обеспечения повышенной производительности. Виртуальные машины vCPU планируются на одном и том же физическом ядре ЦП с гиперпоточностью (Hyper-threading).
 Чувствительность к задержкам с гиперпоточностью
Чувствительность к задержкам с гиперпоточностью
Настройка высокой чувствительность к задержкам с гиперпоточностью требует аппаратного обеспечения виртуальной машины версии 20 и настраивается в дополнительных параметрах виртуальной машины.
 Настройка чувствительности к задержкам с HT
Настройка чувствительности к задержкам с HT
Упрощенная конфигурация виртуальной NUMA
vSphere 8 и аппаратная версия ВМ 20 позволяют использовать vSphere Client для настройки топологии vNUMA для виртуальных машин.
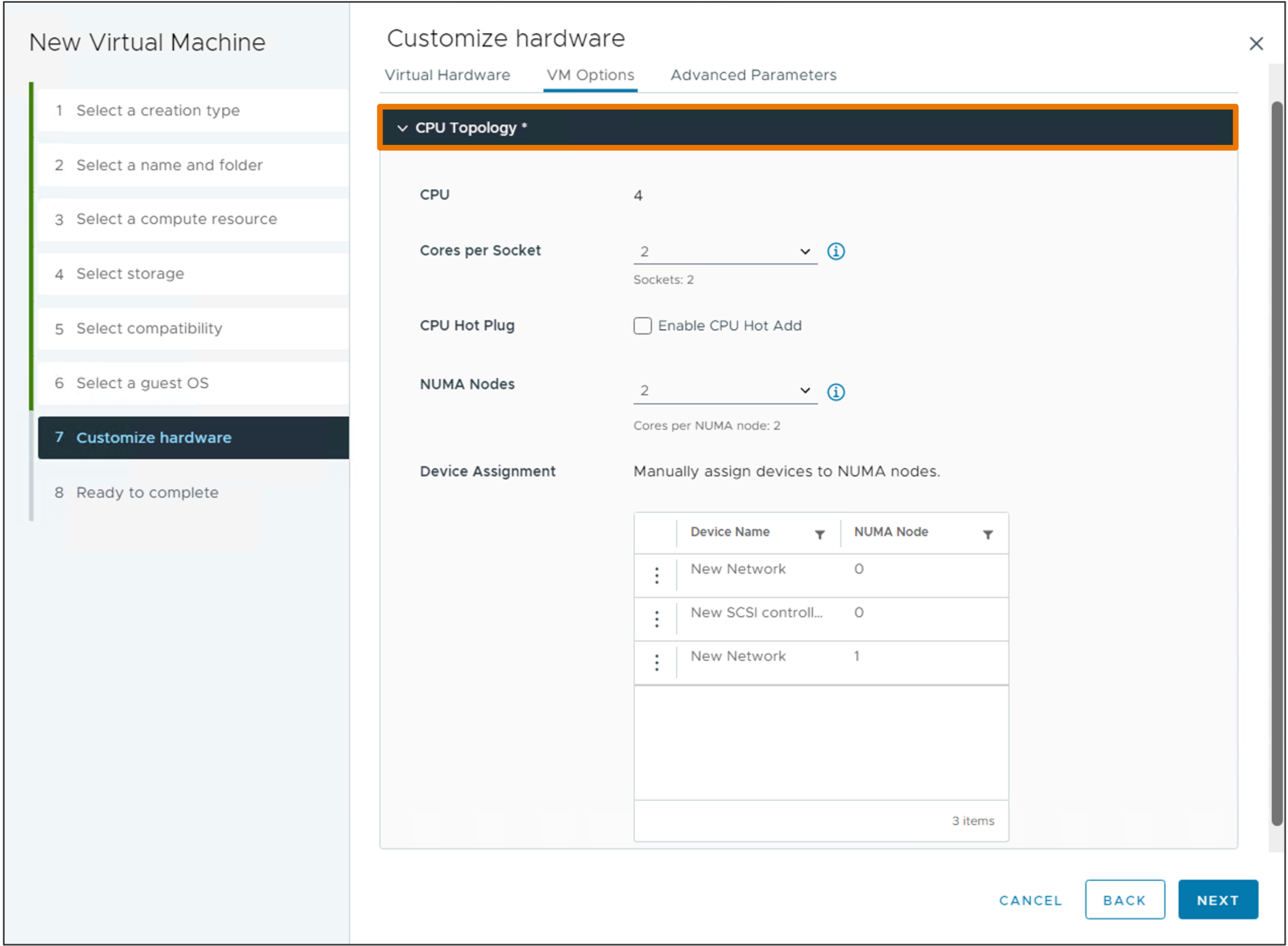 Настройки vNUMA
Настройки vNUMA
На вкладке VM Summary отображается новая плитка топологии CPU, отображающая текущую топологию.
 Плитка vNUMA
Плитка vNUMA
Совместное использование данных vSphere и гостевых систем на основе API
Наборы данных vSphere DataSets обеспечивают простой способ распространения небольших, редко меняющихся данных между уровнем управления vSphere и гостевой операционной системой, запущенной на виртуальной машине с установленными VMware Tools. В качестве примеров могут использоваться состояние развертывания гостевой системы, конфигурация гостевого агента или управление инвентаризацией гостевой системы. vSphere DataSets живут вместе с объектом виртуальной машины и перемещаются вместе с ней в случае миграции, даже между экземплярами vCenter Server.
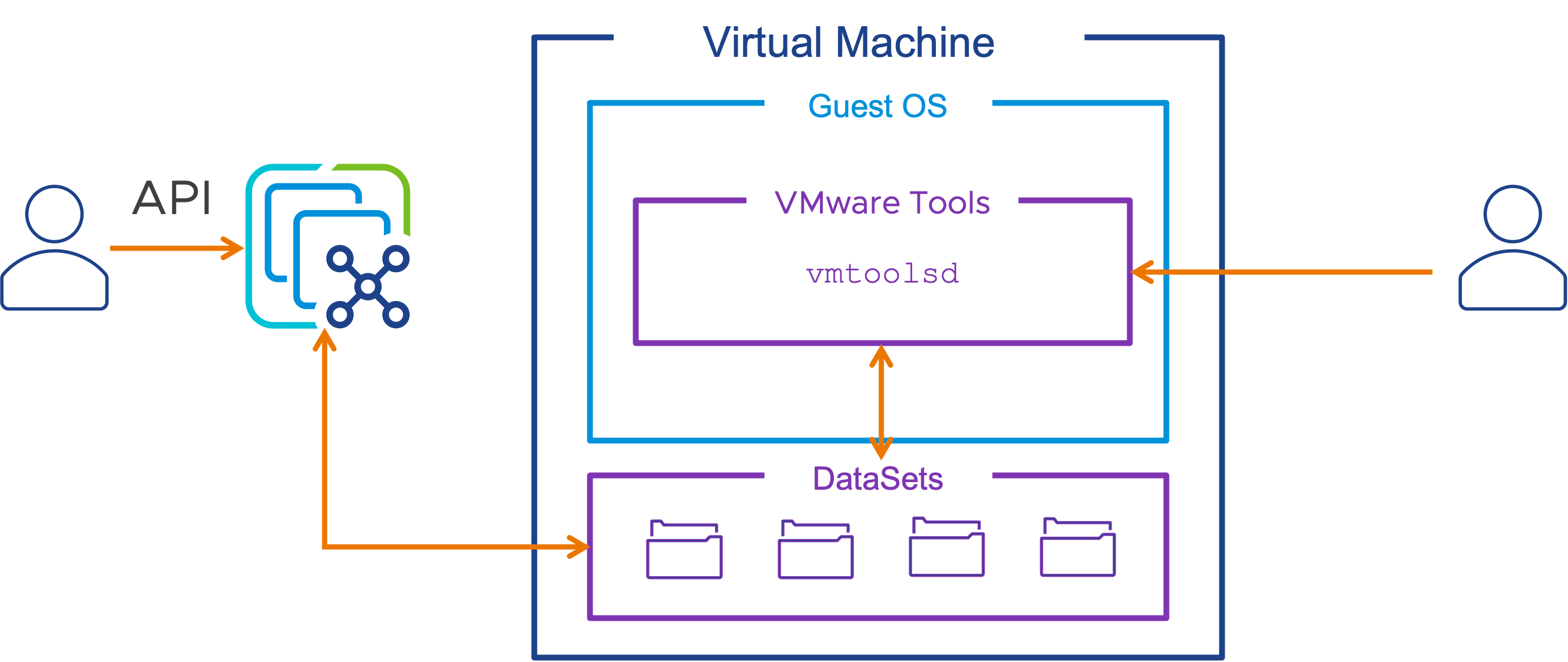 Наборы данных vSphere DataSets
Наборы данных vSphere DataSets
Управление ресурсами
Улучшенная производительность DRS
VMware представила новую функцию в vSphere 7.0U3 под названием vSphere Memory Monitoring and Remediation (vMMR). vMMR помогает устранить необходимость в мониторинге, предоставляя статистику работы на уровне ВМ (пропускная способность) и хоста (пропускная способность, скорость пропусков (miss-rates)). vMMR также предоставляет преднастроенные предупреждения и возможность настройки пользовательских предупреждений на основе рабочих нагрузок, выполняемых на ВМ. vMMR собирает данные и обеспечивает видимость статистики производительности, чтобы вы могли определить, регрессирует ли рабочая нагрузка вашего приложения из-за режима памяти.
В vSphere 8 производительность DRS может быть значительно повышена при наличии PMEM за счет использования статистики памяти, что позволяет принимать оптимальные решения о размещении ВМ без ущерба для производительности и потребления ресурсов.
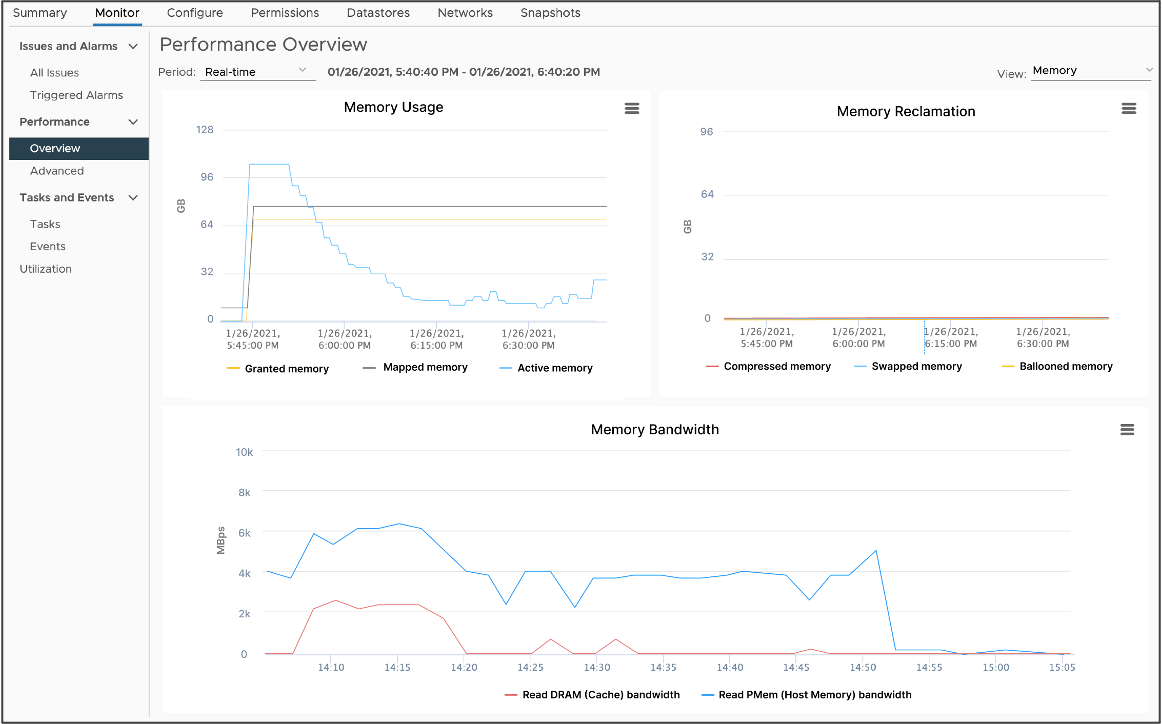 vMMRv2
vMMRv2
Подробнее о постоянной памяти (Pmem): Understanding Persistent Memory (PMem) in vSphere.
Мониторинг энергопотребления и выбросов углекислого газа
vSphere Green Metrics представляет новые метрики энергопотребления для хостов и виртуальных машин. Эти метрики позволяют администраторам отслеживать энергопотребление инфраструктуры vSphere и определять, на основе источников энергии, используемых для питания центра обработки данных, энергоэффективность инфраструктуры vSphere.
Три новые метрики отслеживают :
- power.capacity.usageSystem: Энергопотребление системной деятельности хоста; сколько энергии использует хост, не относящейся к виртуальным машинам.
- power.capacity.usageSystem: Потребление энергии в режиме ожидания; сколько энергии потребляет хост, когда он ничего не делает, кроме как включен.
- power.capacity.usageVm: Потребление энергии хостом из-за рабочих нагрузок ВМ; сколько энергии использует хост для выполнения рабочих нагрузок ВМ.
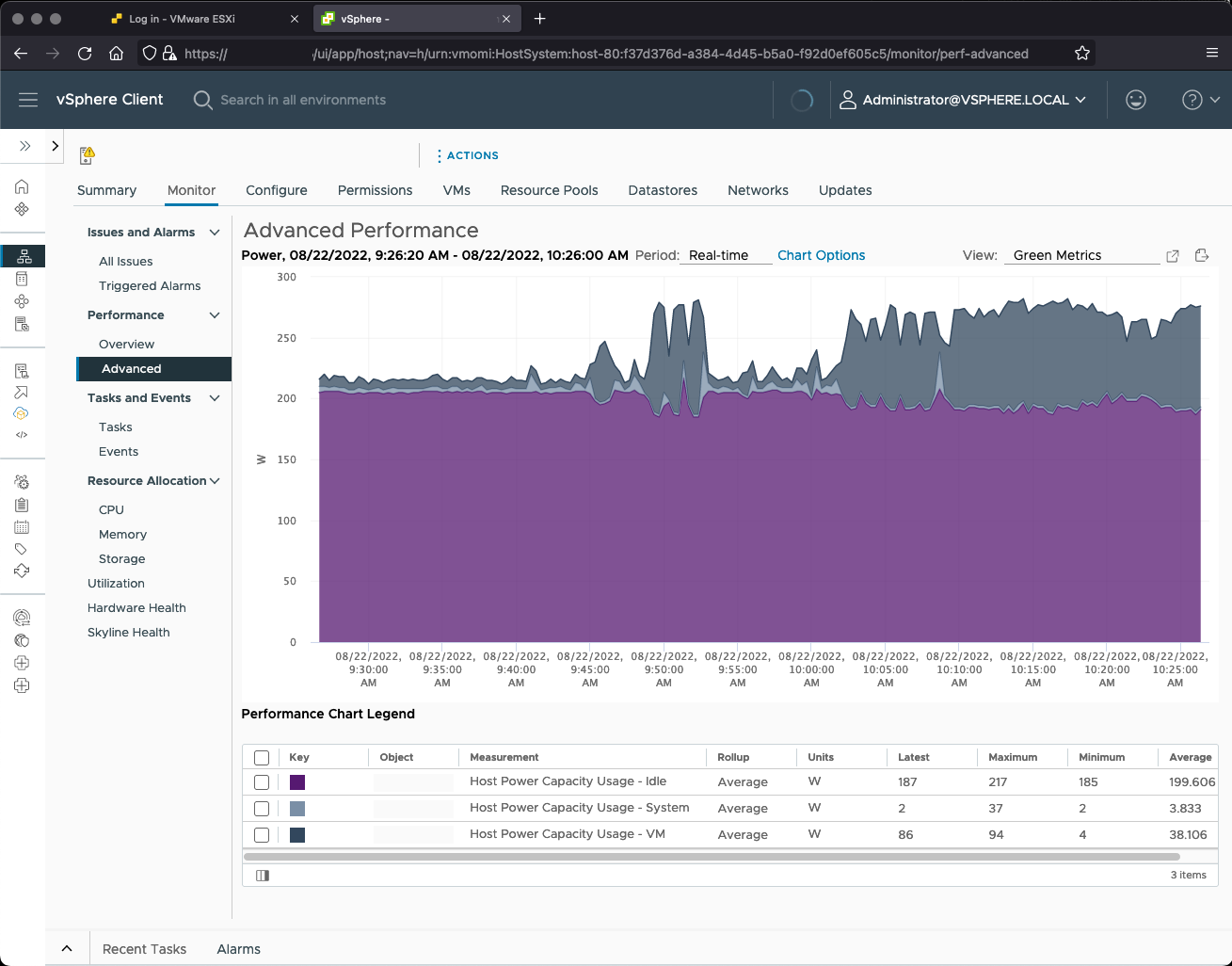 Экометрики в vCenter
Экометрики в vCenter
Безопасность и соответствие
vSphere стремится быть безопасной с самого начала. В vSphere 8 приняты дополнительные меры, чтобы сделать vSphere безопасной по умолчанию.
 Функции безопасности vSphere 8
Функции безопасности vSphere 8
Предотвращение выполнения ненадежных двоичных файлов: В ESXi 8.0 по умолчанию включена опция execInstalledOnly. Это предотвращает выполнение двоичных файлов, не установленных через VIB.
Только TLS 1.2: vSphere 8 не будет поддерживать TLS 1.0 и TLS 1.1. Оба эти протокола ранее были отключены по умолчанию в vSphere 7 и теперь удалены в vSphere 8.
Автоматический таймаут SSH: Доступ к SSH отключен по умолчанию, а в vSphere 8 введен таймаут по умолчанию для предотвращения затягивания сеансов SSH.
Демоны в песочнице: Демоны и процессы ESXi 8.0 запускаются в собственном домене “песочницы”, где процессу доступны только минимально необходимые разрешения.
Прекращение использования Trusted Platform Module (TPM) 1.2: ESXi 8.0 отображает предупреждение во время установки или обновления, если присутствует устройство TPM 1.2. Установка или обновление не предотвращается:
|
1 |
This host has TPM1.2 hardware which is no longer supported. For full use of vSphere features, use TPM 2.0. |