В продолжении цикла
публикую перевод статьи What’s New in Performance for VMware vSphere 7.x?
В основе каждого выпуска VMware vSphere лежит множество улучшений производительности и масштабируемости. Платформа vSphere 7.x продолжает обеспечивать лучшую в отрасли производительность и функции для успешной виртуализации и управления вашим программно-определяемым центром обработки данных.
Последний технический документ “What’s New in Performance for VMware vSphere 7?” охватывает VMware vSphere 7.0, U1, U2 и U3. Некоторые основные моменты включают:
Представлено в vSphere 7.0
Выборочная чувствительность к задержкам: Эта новая функция позволяет виртуальной машине подключать подмножество своих vCPU к отдельным ядрам для повышения производительности. Обратите внимание, что это усовершенствование существующей настройки чувствительности к задержкам виртуальной машины, которая подключает все vCPU в виртуальной машине к ядрам. Привязка определенного подмножества vCPU снижает требования к ресурсам при сохранении необходимой производительности. Теперь мы можем продемонстрировать рабочие нагрузки, выполняемые на прикрепленных vCPU, которые показывают аналогичную или лучшую производительность независимо от того, используется ли настройка чувствительности к задержкам для отдельных CPU или для всей ВМ.

Усовершенствования vMotion: Оптимизация предварительного копирования памяти, свободную/неплотную установку трассировки страниц (Loose Page Trace Install – для трассировки используется один vCPU вместо всех, как было ранее), улучшенная гранулярность таблиц страниц и усовершенствование фазы переключения. Эти функции предназначены для поддержки vMotion “монструозных” ВМ (ВМ с большим числом vCPU), но также полезны для всех размеров vMotion. Подробнее в статье vSphere 7 – vMotion Enhancements.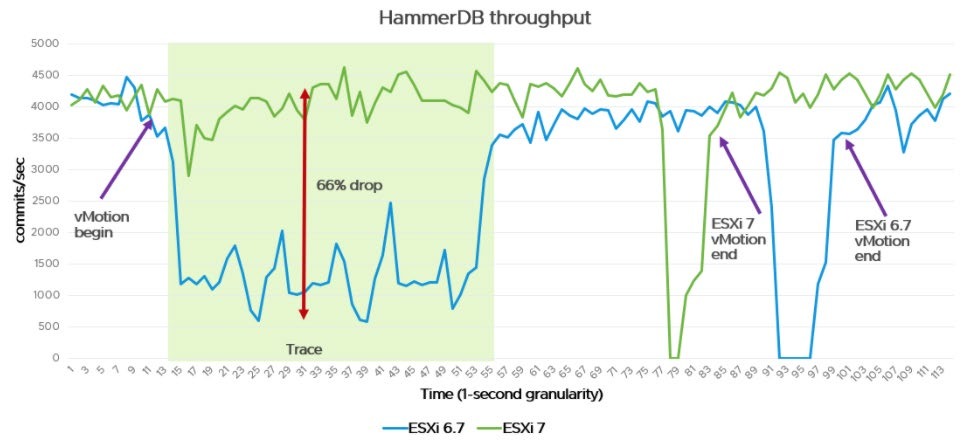
Устройство точных часов: Поддерживает точный учет времени в кластере для чувствительных ко времени рабочих нагрузок.
Представлено в vSphere 7.0 U1
Паравиртуальный RDMA и собственные конечные точки: Повышает производительность приложений и кластеров, использующих RDMA для связи с устройствами хранения и массивами.
Усовершенствования МонстроВМ: Особенности включают расширение физического адреса, оптимизацию адресного пространства, улучшенное понимание NUMA для гостевых операционных систем и более масштабируемые методы синхронизации. Благодаря этому размер виртуальных машин теперь может достигать 768 vCPU и 24 ТБ ОЗУ. Хосты ESXi с процессорами AMD могут поддерживать виртуальные машины с вдвое большим количеством vCPU (256) и до 8 ТБ оперативной памяти.
Усовершенствования vMotion: Значительное повышение производительности при миграции виртуальных машин. Среди прочего, это изменение архитектуры предварительного копирования памяти с использованием инновационного механизма трассировки страниц, что значительно снижает влияние на производительность гостевых рабочих нагрузок во время живой миграции и значительно сокращает продолжительность vMotion. Данные о производительности рабочих нагрузок Tier-1 показывают, что эти оптимизации могут масштабироваться до сотен vCPU и терабайтов памяти.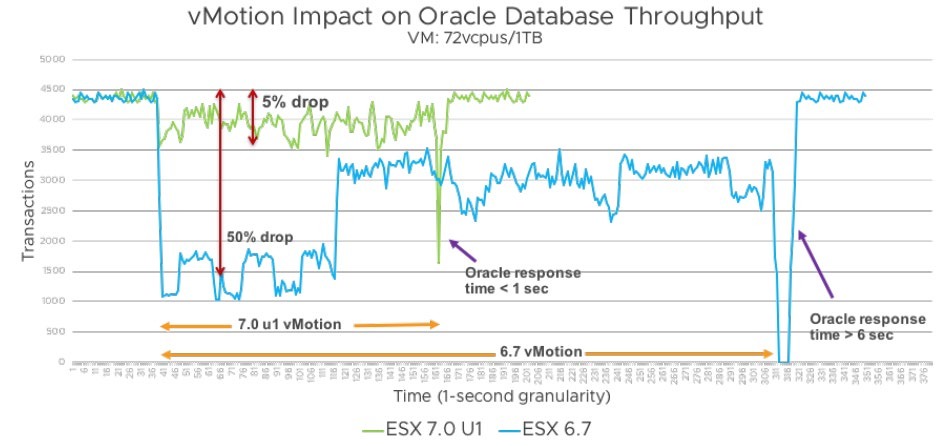
NVMe over Fabrics (NVMe-oF): Спецификация протокола, обеспечивающая подключение хостов к высокоскоростным флэш-накопителям через сетевые ткани с использованием протокола NVMe. Фабрики, поддерживаемые vSphere 7.0 U1, включают Fibre Channel (FC-NVMe) и RDMA (RoCE v2). Результаты бенчмарка показывают, что FC-NVMe стабильно превосходит SCSI FCP в виртуализированных средах vSphere, обеспечивая более высокую пропускную способность и меньшую задержку.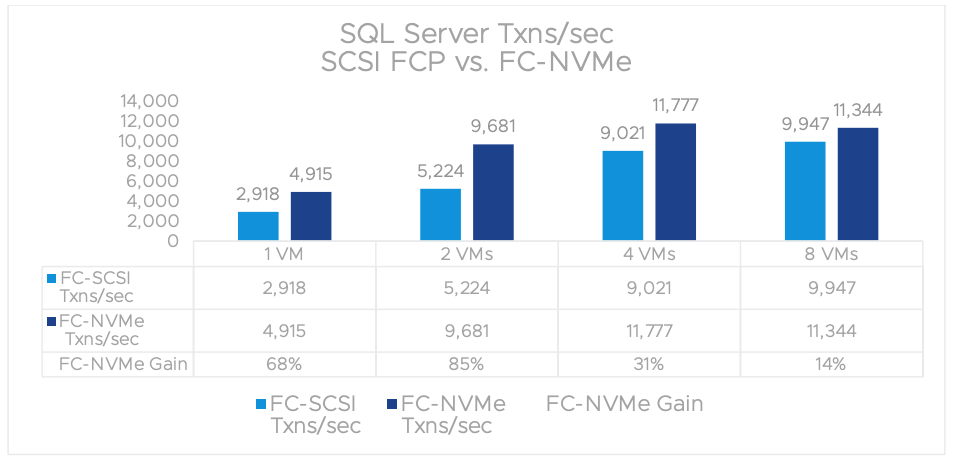
Представлено в vSphere 7.0 U2
Поддержка корпоративной инфраструктуры NVIDIA: Архитектура NVIDIA Ampere позволяет выполнять высококлассные рабочие нагрузки по обучению ИИ (искусственный интеллект)/МО(машинное обучение) и получению логических выводов МО, используя ускорение операции с помощью GPU A100. Поддержка vSphere для GPU A100 обеспечивает производительность ИИ мирового класса: до 20 раз выше, чем у GPU предыдущего поколения. Кроме того, вы получаете производительность, близкую к производительности “голого железа”, и такие технологии, как связь GPU Direct, которые обеспечивают более высокую производительность при масштабировании рабочих нагрузок (добавление большего количества ВМ в систему vSphere).
Повышение производительности для процессоров AMD Zen: vSphere 7.0 U2 включает планировщик процессора, архитектурно оптимизированный для AMD EPYC. Этот планировщик разработан для использования преимуществ нескольких кэшей последнего уровня на процессорное гнездо (LLC per socket) , предлагаемых процессорами AMD EPYC. Обширная оценка производительности с использованием корпоративных и микробенчмарков показала, что планировщик ЦП в vSphere 7.0 U2 достигает на 50% более высокой производительности на этих процессорах, чем vSphere 7.0 U1. Оптимизация процессоров AMD Zen позволяет использовать большее количество ВМ или развертывать контейнеры с более высокой производительностью.
Больше оптимизации рабочих нагрузок, чувствительных к задержкам: Рабочие нагрузки, чувствительные к задержкам, например, в финансовых и телекоммуникационных приложениях, могут получить значительный выигрыш в производительности благодаря оптимизации задержек ввода-вывода и джиттера в ESXi 7.0 U2.
Автоматическое масштабирование vMotion: vSphere vMotion в версиях до vSphere 7.0 U2 не утилизирует полностью сетевые карты с высокой пропускной способностью (такие как 25, 40 и 100 GbE) без дополнительной настройки, так как по умолчанию vMotion использует один поток для обработки процесса миграции ВМ.
В vSphere 7.0 U2 процесс vMotion автоматически увеличивает количество потоков в соответствии с пропускной способности физических сетевых карт, используемых для сетей vMotion. 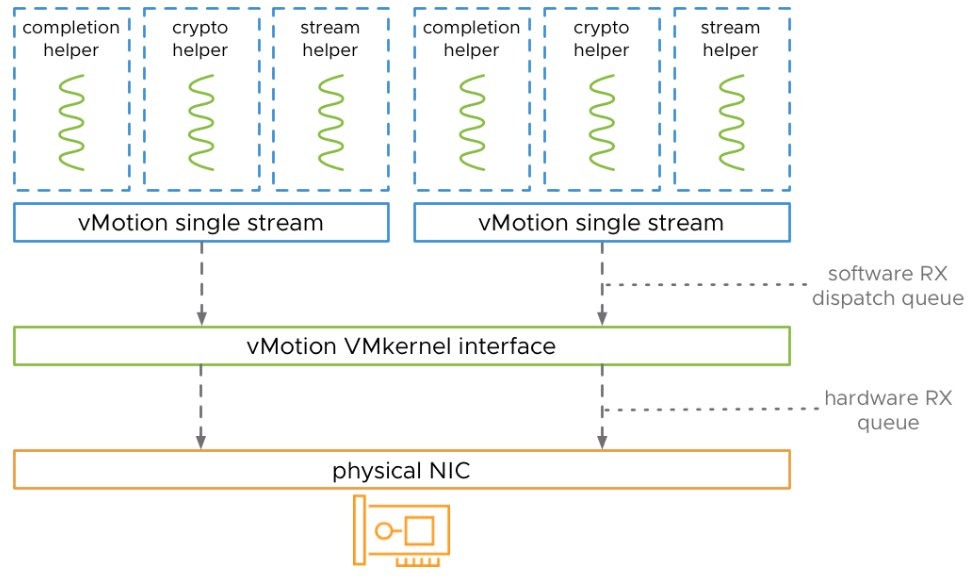
Представлено в vSphere 7.0 U3
Ещё больше оптимизаций рабочих нагрузок, чувствительных к задержкам: ESXi 7.0 U3 был дополнительно оптимизирован для того, чтобы приложения с ультранизкой задержкой работали лучше с меньшим дрожанием и помехами, в частности, пограничные приложения реального времени.
vSphere Memory Monitoring and Remediation (vMMR): Объем памяти DRAM составляет примерно 50-60% стоимости сервера. И это не линейно – 1 ТБ DRAM составляет примерно 75% от стоимости сервера. Таким образом, существует огромная потребность в снижении стоимости DRAM. Одним из решений является Intel Optane Persistent Memory Mode, в котором аппаратное обеспечение скрывает DRAM в качестве кэша и раскрывает PMem как память системы.
Поддержка NVMe через TCP/IP: позволяет использовать вездесущую сетевую инфраструктуру TCP/IP для трафика хранения данных, который лучше оптимизирован для флэш- и твердотельных накопителей. Благодаря этому усовершенствованию организации могут добиться более высокой производительности и меньшей задержки при меньших затратах.
P.S. Перевод выполнен комбинацией машинного обучения и человеческого интеллекта в пропорции 90/10. Добавлены картинки из презентации. Если есть пожелание поправить чего, то пишите в комментарии.