Всем привет, я krokokot, и это моя первая статья на vmind.ru. Поэтому, как говорится, не бейте, а если все же будете бить – то не сильно и не ногами.
Поводом для статьи стал виртуальный спор в кругу нескольких весьма продвинутых админов сред виртуализации, а также приближенных к ним лиц, т.е. – меня. Предметом спора была пропускная способность сетей в гипервизоре VMware ESXi, а точнее – производительность паравиртуального сетевого адаптера VMXNET3 в условиях высокой нагрузки. Гугл выдавал на эту тему ссылки типа
http://rickardnobel.se/vmxnet3-vs-e1000e-and-e1000-part-2/
содержащие весьма противоречивые данные, к тому же многие тесты датировались 2012-2014 годами выпуска. Посему ваш покорный слуга принял решение провести небольшое тестирование самостоятельно.
Часть 1. Тестирование конфигурации с настройками по умолчанию.
Никаких особых планов тестирования не писалось. Было только понимание, что производительность – вещь никакая не абстрактная, а очень даже конкретная. Поэтому и измерения тоже должны быть конкретными – берем конкретный хост, конкретную ОС и конкретно измеряем пропускную способность.
«Под рукой» оказался практически незагруженный хост на базе материнской платы ASUS X99-E с процессором Intel Xeon E5-2620 v4 2.1 ГГц, заведомо достаточное количество RAM DDR4 2133. Версия гипервизора ESXi 6.5.0 Update 1 (Build 5969303).
Первым делом были созданы две ВМ с параметрами 4vCPU, 4 Gb RAM (All locked), 40 Gb disk (on paravirtual SCSI controller), сетевой адаптер VMXNET3. Версия ВМ – 13.
В каждую ВМ был установлен Windows Server 2012R2 со всеми обновлениями на 19.10.2017 и VMware Tools 10.1.7 (Build 5541682). Брандмауэр Windows выключен. На сетевые адаптеры внутри ВМ назначены статические IP-адреса. Для чистоты эксперимента виртуальные сетевые адаптеры обеих ВМ были подключены в отдельную порт-группу на отдельном виртуальном коммутаторе. Виртуальный коммутатор не подключался ни к одному физическому адаптеру, т.к. исследовалась производительность не конкретной сетевой карты, а паравиртуального адаптера и виртуального коммутатора.
Для замеров пропускной способности виртуальной сети между этими двумя ВМ использовался iperf 3.1.3 x64. На основании прошлого опыта использования iperf было принято решение тестировать несколько раз, с изменением количества TCP потоков от 1 до 16.
ВМ TEST2 выполняла роль сервера (команда iperf –s). Чтобы уж совсем придать «академичность» тестированию в соответствии с остатками моих знаний по метрологии замеры производились 3 раза (для последующего усреднения результатов) по 20 секунд, с паузой в 3 секунды. Предварительные измерения показали наличие артефактов (или, если угодно – статистических выбросов) в первые несколько секунд измерений:
Поэтому первые 5 секунд после запуска теста решено было отбрасывать и не учитывать в результатах измерений. Благо у iperf для этого есть специальная опция –O. Также трижды производились замеры в обратном направлении трафика (опция iperf -R). Для всего этого на ВМ TEST1 был написан и запущен небольшой скрипт:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
FOR /L %%i IN (1,1,16) DO ( FOR %%j IN (1,2,3) DO ( ECHO %date% %time%>>testresult01.log iperf3.exe -c 10.10.1.11 -t25 -O5 -P%%i>>testresult01.log timeout 3 > nul ) FOR %%j IN (1,2,3) DO ( ECHO %date% %time%>>testresult01.log iperf3.exe -c 10.10.1.11 -t25 -O5 -P%%i -R>>testresult01.log timeout 3 > nul ) ) |
В результате были получены следующие сырые данные: <файл testresult01.log>
Offtopic: команда ECHO %date% %time% была включена в скрипт чтобы примерно отслеживать время выполнения тестов. Команда прекрасно работала из командной строки, в скрипте же выдавала почему-то один и тот же результат. Разбираться не стал. В следующем скрипте заменил
|
1 |
ECHO %date% %time%>>testresult01.log |
на
|
1 2 |
date /t>>testresult02.log time /t>>testresult02.log |
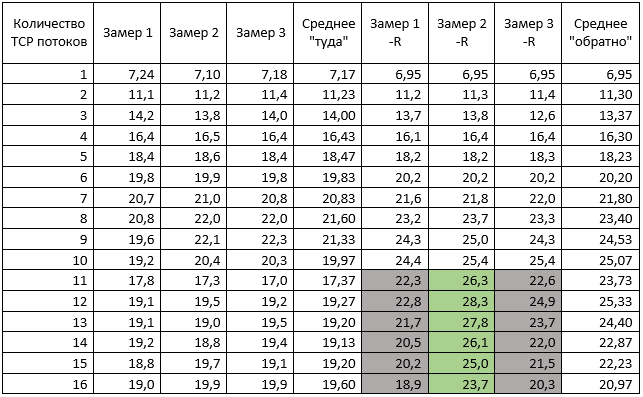
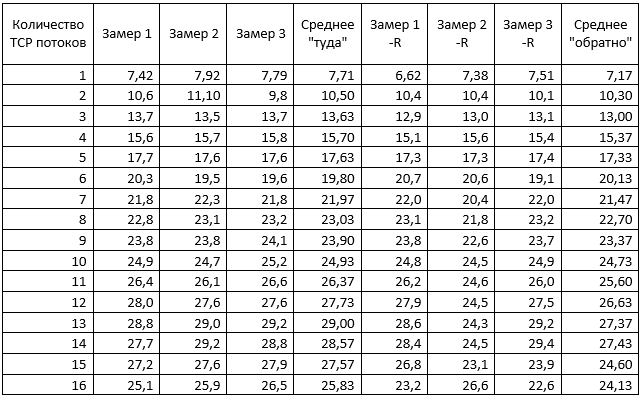
Быстрый парсинг сырого лога в табличку Excel дал вот такие результаты:
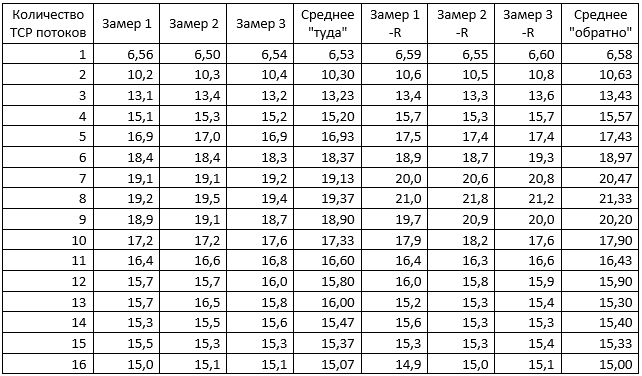
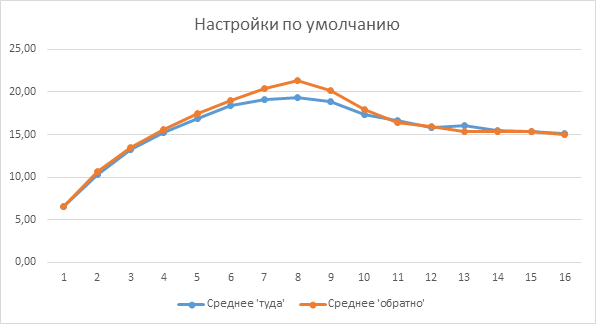
Налицо два явления: плавный рост пропускной способности до 8 потоков, а затем снижение и почти стабилизация. И различие скорости передачи в зависимости от направления. Последнее заинтересовало, и для проверки был проведен аналогичный замер, при котором ВМ «поменяли ролями»: TEST1 стала сервером, скрипт же выполнялся на TEST2. Результаты этого теста были аналогичными, для сокращения объема статьи их не привожу, но и объяснения им, кроме как «это особенность работы iperf в данной среде» на этот момент не было.
Часть 2. Оптимизация.
Нет ничего, что человек, а в особенности – админ среды виртуализации, не мог бы сделать лучше. Наверное. 20 гигабит в секунду на 8 TCP-потоках на дефолтных настройках были неплохим результатом, но я попытался его улучшить. Кто же знал, что все будет совсем не так просто, как предполагалось…
Включаем JUMBO FRAME.
Первое, что пришло на ум: пропускную способность можно повысить, включив Jumbo packet, т.е. увеличив MTU сетевого адаптера до 9000. В реальности, чтобы это работало, нужно, разумеется, чтобы все коммутаторы и маршрутизаторы между хостами также поддерживали MTU 9000. Поэтому включаем Jumbo frame в нашем виртуальном коммутаторе:
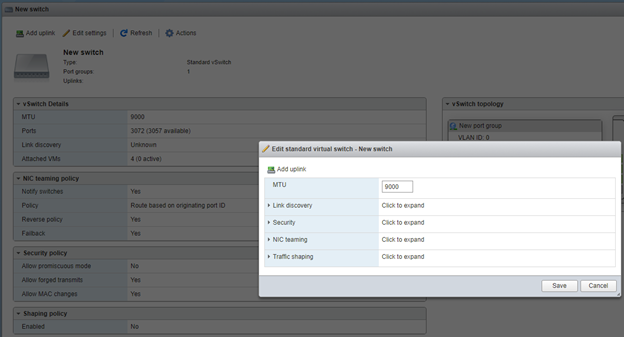
И смело лезем на обоих ВМ в настройки сетевого адаптера и делаем так:
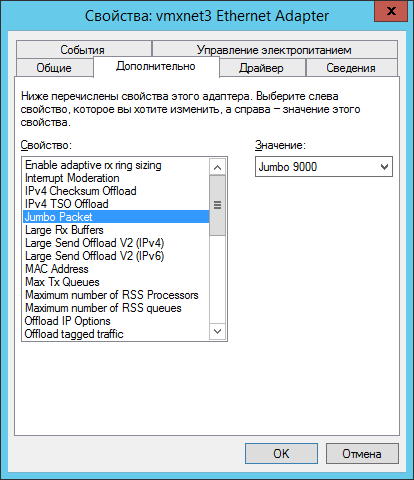
Кстати, эту же настройку можно делать через PowerShell командой
|
1 |
Set-NetAdapterAdvancedProperty Ethernet0 -DisplayName "Jumbo Packet" -DisplayValue “Jumbo 9000” |
А смотреть все настройки адаптера командой
|
1 |
Get-NetAdapterAdvancedProperty: |
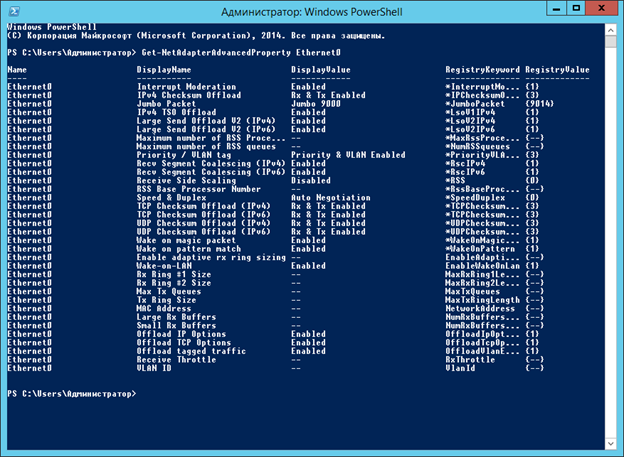
Запускаем немного подправленный скрипт:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
set logfile=testresult02.log FOR /L %%i IN (1,1,16) DO ( FOR %%j IN (1,2,3) DO ( date /t>>%logfile% time /t>>%logfile% iperf3.exe -c 10.10.1.10 -t25 -O5 -P%%i>>%logfile% timeout 3 > nul ) FOR %%j IN (1,2,3) DO ( date /t>>%logfile% time /t>>%logfile% iperf3.exe -c 10.10.1.10 -t25 -O5 -P%%i -R>>%logfile% timeout 3 > nul ) ) |
и идем пить чай с печеньками, ибо молотить он будет, по данным предыдущего замера, около часа. И действительно: <файл testresult02.log>
Парсим:
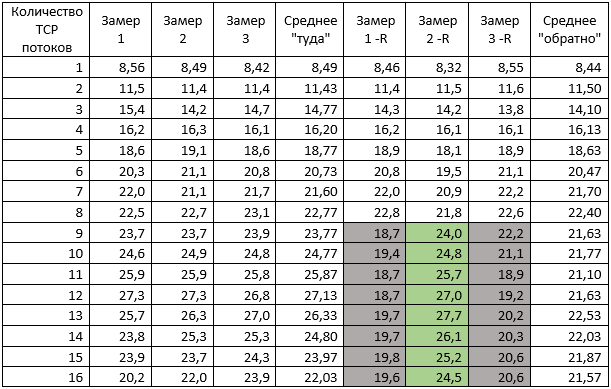
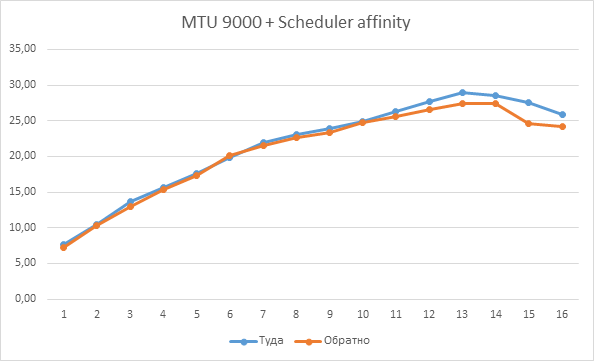
Для удобства сравнения накладываем график MTU 9000 на ранее полученный с MTU 1500:
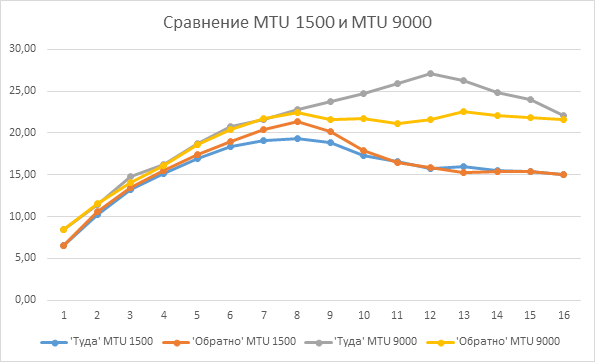
Поведение графика «Туда» логично и немного предсказуемо. Но вот «Обратно» преподносит сюрприз. Особенно если сравнить значения второго «реверсного» замера с первым и третьим при TCP от 9 (выделено в таблице выше серым и зеленым): второй замер с опцией –R показывает шикарный результат 27 гигабит в секунду, но предыдущий и следующий замеры явно лажают. Это «ж-ж-ж» случилось явно неспроста, повторный тест с «обменом ролями», когда TEST1 стал сервером, а ТЕСТ2 – клиентом, это подтвердил: <файл testresult02-1.log>
27 гигабит в секунду по сравнению с дефолтными 20-ю – неплохой, но нестабильный результат, поэтому было принято решение найти, «кто же там жужжит».
Часть 3. Поиск «ж-ж-ж».
Далее последовали: курение файн и факинг мануалов, множество тестовых запусков, тяжелые раздумья, снова курение мануалов и далее по кругу. Тест упорно показывал то 27 гигабит, то не поднимался выше 20. Единственным моим предположением, объясняющим происходящее, стало следующее: 20 с гаком гигабит в секунду – трафик, на обработку которого в виртуальном коммутаторе хост обязан потратить ощутимое количество процессорного времени. В случае, если это процессорное время шедулер распределяет «условно оптимально» и не пересекает с нагрузкой от ВМ – мы имеем тест со скоростью 27 гигабит. Если же «ошибается» – ВМ конфликтует за ядро pCPU с обработчиком виртуального коммутатора, и скорость теста падает.
Для косвенного подтверждения этого предположения я выставил обеим ВМ Scheduling Affinity на «четные» pCPU:
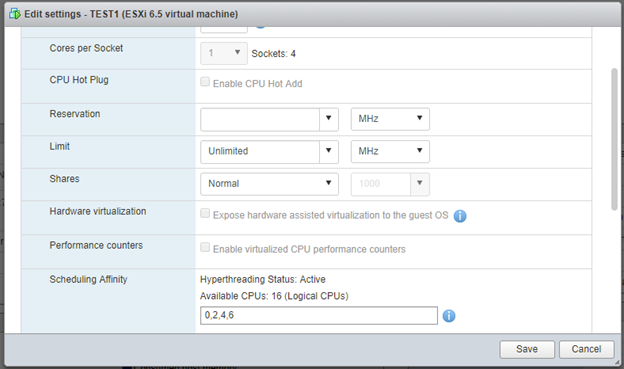
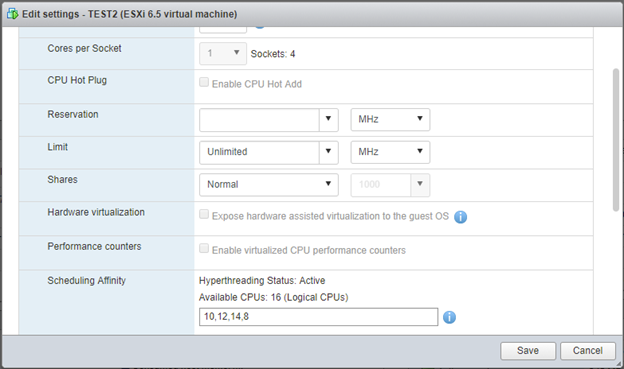
Offtopic: тут я несколько раз вводил «8,10,12,14» , но после нажатия Save и повторно Edit веб клиент упорно показывает «10,12,14,8». Ну да и бог с ним, вроде работает правильно.
Тест стал проходить намного стабильнее, esxtop показал косвенное подтверждение моего предположения:
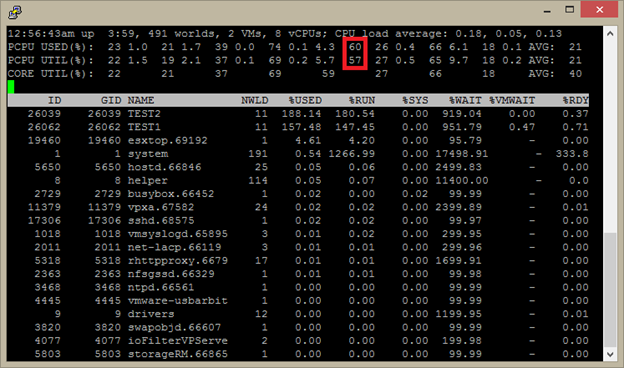
Т.к. на хосте запущены только две мои тестовые ВМ, и для них обеих прописано Scheduling Affinity на pCPU, соответствующие физическим ядрам без гипертрейдинга – эти, в красной рамочке, периодически «прыгающие» между «нечетными» (гипертрейдинговыми) pCPU 50-70 процентов нагрузки и есть, по всей видимости, процессорное время, требуемое хосту для обработки трафика внутри виртуального коммутатора.
ВМ с Affinity – не лучшее решение, но другого я пока не нашел. Копал в сторону «можно ли выделить отдельный pCPU для работы процесса виртуального коммутатора» – не преуспел. Зато в результате мы имеем стабильно проходящий тест iperf между двумя виртуальными машинами: <файл testresult04.log >
Итого – имеем скорость «без какой-то копеечки» 30 гигабит в секунду.
При этом настройки адаптера в обеих ВМ выглядят так:
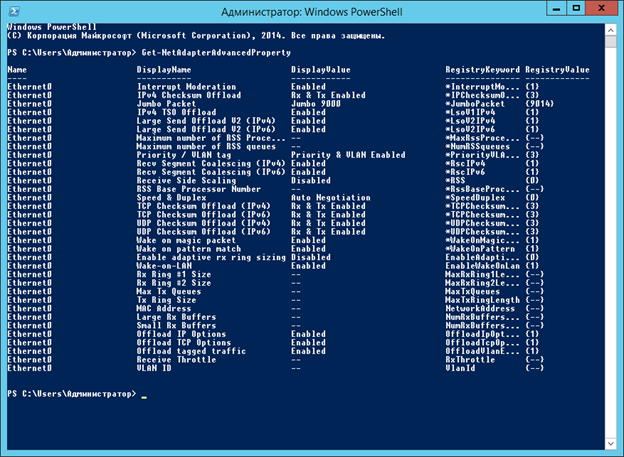
Единственное отличие в этой картинке от аналогичной, приведенной ранее:
|
1 |
Set-NetAdapterAdvancedProperty Ethernet0 -DisplayName ”Enable adaptive rx ring sizing” -DisplayValue “Disabled” |
С «Enabled» или пустым полем производительность теста была ниже.По аналогии с «Включаем JUMBO FRAME» планировалось также «Включаем Receive Side Scaling», и «Настраиваем размеры буферов приема и буферов передачи», и даже «Меняем количество vCPU», однако реальность оказалась суровее. Перепробована куча вариантов настроек и ВМ, и сетевого адаптера. Описывать каждую нет смысла, т.к. результат теста они не улучшали. Поэтому за кадром остались некоторые очевидные и не совсем вещи, о которых имеет смысл сказать:
- Уменьшение количества vCPU в тестовых ВМ ведет к уменьшению значений в тестах. Увеличение – тоже. Возможно, на хосте с большим количеством ядер в процессоре будет иначе. Хотя я в этом сомневаюсь – ни в одном тесте ни один из процессоров внутри ВМ не показал полку в 100%.
- Включение Receive Side Scaling (RSS) в настройках сетевого адаптера в отсутствии собственно физического адаптера, этот RSS реализующий, ведет к падению пропускной способности теста. А еще там есть хитрый параметр RSS Base Processor Number, логику работы которого удалось постичь не сразу: https://docs.microsoft.com/ru-ru/windows-hardware/drivers/network/setting-the-number-of-rss-processors
Выводы:
Паравиртуальный адаптер VMXNET3 – это жутко близко и запредельно быстро.
Планы: Попробовать то же самое с Linux-based оерационной системой. Например, с активно применяемой мной в жизни RouterOS Cloud Hoster Router. Вооруженный новыми знаниями я попробую штурмануть рубеж в 40 гигабит в секунду между ВМ.
P.S. А вот тут архив с результатами работы скрипта testresult0#.log.
Тестирование производительности VMXNet3. Часть 2: RouterOS Cloud Hosted Router
Спасибо за статью!
Спасибо за статью. Если интересно, в вашем batch-скрипте не работал вывод “ECHO %date% %time%>>testresult01.log” потому что не была включена опция EnableDelayedExpansion и вы неправильно обращались к переменным. Если эта опция не установлена, то CMD высчитывает переменные на стадии парсинга. В вашем случае нужно чтобы расчёт переменных происходил в runtime. Для этого необходимо добавить команду SETLOCAL EnableDelayedExpansion и получать текущее значение переменных с помощью !time! (%time% будет содержать значение при инициализации). Либо сделать цикл с помощью IF и CALL и ручным увеличением переменной, вместо FOR /L.
Благодарю покорнейше за уточнение! Так и знал, что где-то там порывшаяся собака присутствует, но времени разбираться не было. Скрипт исправлю.
Было бы интересно посмотреть, как подействует общая Advanced настройка хоста
Net.NetVMTxType = 3
(выделение на каждый виртуальный ethernet от 2 до 8 transmit threads)
на скорость передачи локального трафика
В “vSphere 6 Foundations Exam Official Cert Guide” советуют не использовать vmxnet3 для Jumbo Frame в гостевой ОС:
“However, there is a known issue with the vrnxnet3, so you should choose either the vmxnet2 (enhanced vmxnet) or the el000 vnic, whichever is best for the OS on the VM.”
Я прям озадачился, т.к. считаю vmxnet3 “must-have”. С ходу обнаружил только “Large packet loss at the guest operating system level on the VMXNET3 vNIC in ESXi (2039495)”.