Возникла задача развернуть пару виртуалок Avaya.
На третьем шаге мастер по импорту шаблонов споткнулся и сказал, что сертификат vCenter недоверенный.
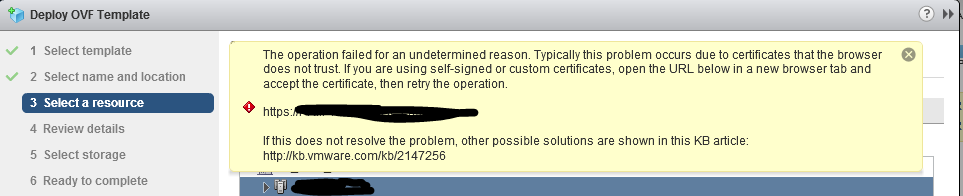
Решение стандартное: сертификату vCenter рабочая станция должна доверять, причем подключаться вы должны по полному имени (FQDN) vCenter.
Один из вариантов – это добавить в доверенные узлы на вашей рабочей станции тот центр сертификации, которым воспользовался vCenter.
Для просмотра сертификата vCenter нажмите на красный значок в адресной строке:
![]()
Затем перейдите на вкладку “Путь сертификации”, выберите сертификат центра сертификации (самый верхний) и нажмите “Просмотр сертификата”.

Указанный сертификат необходимо установить в доверенные центры сертификации “Local Machine” на вашей рабочей станции.
После этого перезапустите браузер и подключитесь по полному имени сервера, указанному в сертификате в поле “Кому выдан” или CN.

Но и это еще не все – ряд виртуальных машин отказывался импортироваться, выдавая ошибки несоответствия.
Для решения данной проблемы я исключил проверку целостности OVA-архива, распаковав его и удалив файлы .cert и .mf.
P.S. соавтор Mr_Nobody подсказывает, что при развертывании через Host Client сертификаты игнорируются.
